Web Scraping Amazon with JavaScript: How to bypass challenges like CAPTCHAs and IP blocks, and ensure seamless data collection

Photo by Sagar Soneji (Pexels)
Whether you're a developer creating a product, an entrepreneur studying the competition, or a shopper hunting for the best deal, the vast amount of data available on e-commerce sites like Amazon can be a game-changer. But how can you access this data? The answer is web scraping --- a method for extracting data directly from websites using a custom-built scraper.
With its ability to swiftly gather information like product listings, customer reviews and prices, web scraping can provide invaluable insights that help you make informed decisions, whether you're aiming for market advantage or simply looking for the best deal. However, scraping an e-commerce giant like Amazon presents unique challenges despite its potential to deliver valuable insights.
In this guide, we'll explore how to scrape Amazon using JavaScript. First, we'll address some of the challenges developers face when attempting to scrape Amazon with vanilla JavaScript. Then, we'll introduce a practical solution: Bright Data's Scraping Browser--an automated real browser that can bypass these challenges seamlessly, and is fully compatible with Puppeteer/Playwright/Selenium scripts.
Challenges of Scraping Amazon with Vanilla JavaScript
Scraping data from Amazon, one of the world's largest e-commerce platforms, is no easy feat. The challenges are numerous and often confusing, even for experienced developers and data scientists. If you're planning to scrape an e-commerce site using basic vanilla JavaScript, be prepared for a difficult journey filled with complex issues like rate limiting, browser fingerprinting, and CAPTCHAs. These hurdles, or anti-scraping measures, can make the scraping process not only time-consuming but also a drain on your resources.
For instance, while you might begin with straightforward techniques like sending HTTP requests, parsing HTML, and extracting data, Amazon's advanced anti-scraping measures can quickly complicate things. Taking it a step further by using tools like Puppeteer to control a headless browser programmatically can help, but it still doesn't fully bypass the difficulties. The road ahead can still be fraught with frustration.
Let's take a look at some of these challenges in detail:
- Rate limits: Websites implement rate limiting to protect themselves from being overwhelmed by a flood of requests. As an eager scraper, you'll quickly hit a wall when your IP address or browser gets blocked, accompanied by warnings like, "Slow down!" If you're not cautious, your access to the site you're trying to scrape could be cut off entirely.
- Browser fingerprints: Websites track your behavior by collecting unique identifiers, known as browser fingerprints, which make it obvious you're not a regular user but a bot. Avoiding browser fingerprinting becomes a challenging game of cat and mouse, as websites continuously evolve their detection techniques. If you're unfamiliar with the term, it refers to the process of identifying users through their browser settings and activities.
- CAPTCHAs: Those frustrating challenges that test whether you're a human or a bot --- like selecting images of traffic lights --- are designed to block automated scraping. Overcoming CAPTCHAs with code alone is difficult, requiring the integration of proxies to bypass them. However, selecting the right type of proxy is crucial, as basic datacenter proxies may not always work. Navigating around CAPTCHAs manually is far more complex than it initially seems.
So, while the concept of web scraping using just vanilla JavaScript might seem straightforward or appealing at first, the reality becomes much more complicated when the website you're targeting starts detecting your activity. You'll face numerous challenges and have to implement complex logic in your code to navigate these obstacles before you can even begin collecting data.
This is precisely where the Scraping Browser comes in, to help you work around these limitations. The Scraping Browser will take care of automating IP rotation, CAPTCHA solving, and more on the server-side, so you won't have to spend time incorporating additional block-bypassing logic in your code.
Scraping Browser API - Automated Browser for Scraping
Without further ado then, let's dive into setting up the Scraping Browser before we scrape Amazon.
Setup
The Scraping Browser is a headful browser that runs your Puppeteer/Playwright/Selenium scripts on Bright Data's servers and comes with Bright Data's powerful unlocker infrastructure and proxy network for unsurpassed block bypassing right out of the box. It rotates IP addresses, avoids detection, and gracefully sails through CAPTCHAs without breaking a sweat.
With the Scraping Browser, you can say goodbye to the time-and-resource-consuming practices and third-party libraries associated with most web scraping tasks. Bright Data's cloud platform seamlessly handles the busy-work, allowing you to focus on extracting the data you need.
With all that said, let's now get started with setting up the Scraping Browser.
Obtaining the Required Username and Password for the Scraping Browser
For the purpose of this article, we'll be integrating the Scraping Browser with our Puppeteer script. To connect the Scraping Browser with Puppeteer, we need to first obtain the values Username, Password, and Host from Bright Data's website. Follow these steps to obtain the necessary keys:
- Visit the Scraping Browser page and create a new account for free by clicking on Start free trial/Start free with Google. Once you've finished the signup process, Bright Data will give you a free credit of 5$ for testing purposes.
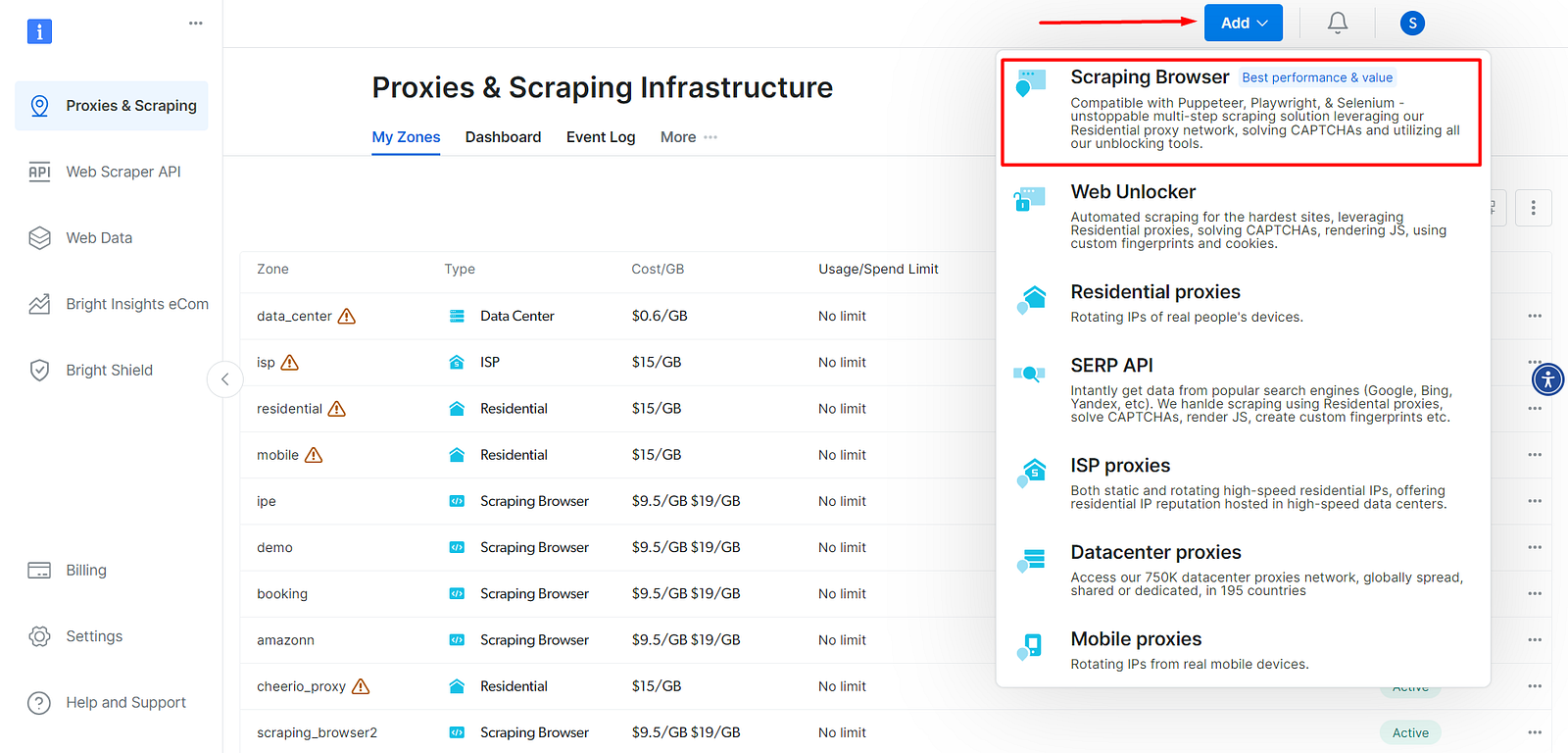
- After the account is created, navigate to the Proxy and Scraping Infrastructure section and click the Add button from the top-right section. Choose Scraping Browser from the list.
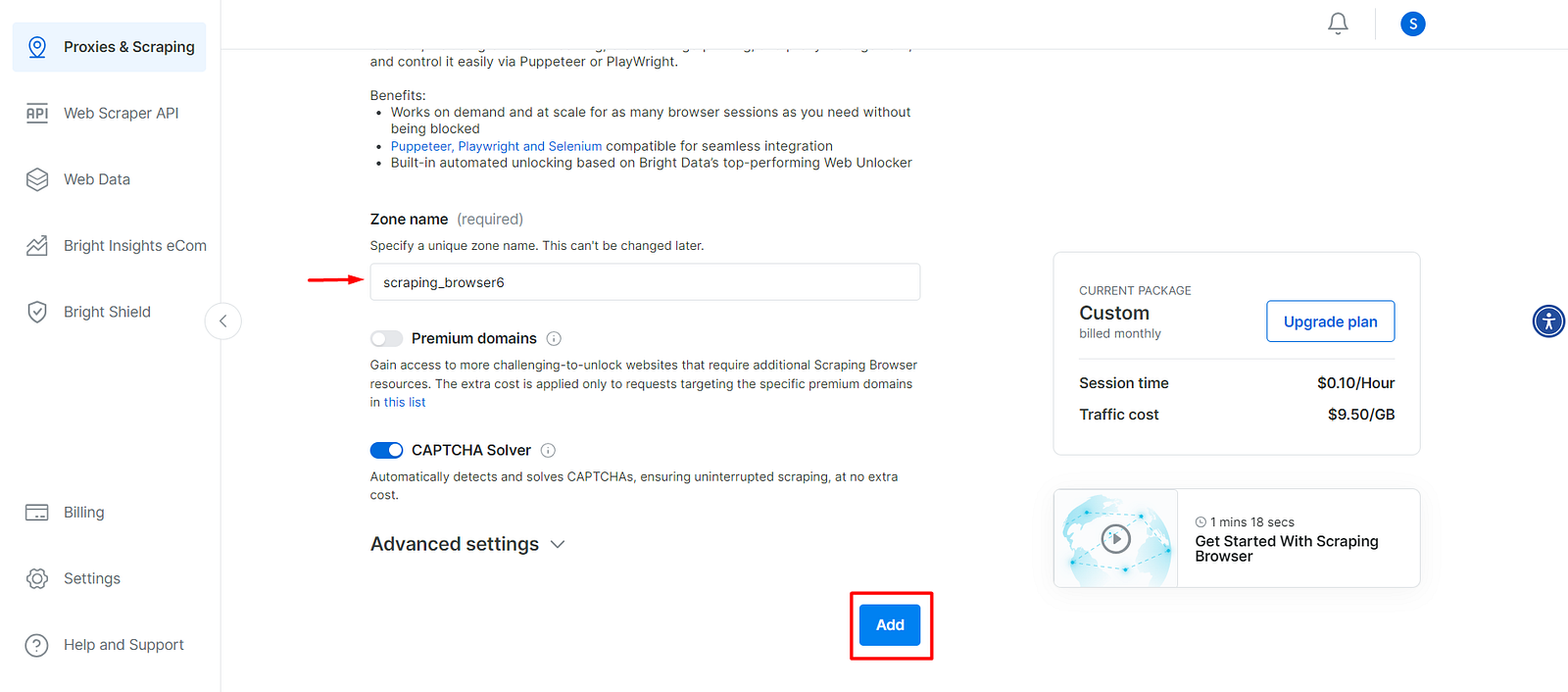
- Give a Zone name to your scraping browser, or move forward with the auto-generated one by clicking on Add.
- After you confirm, the browser is created, and it will take you to a new page with the Access Parameters tab. This is where you'll find the required Username, Password, and Host values.
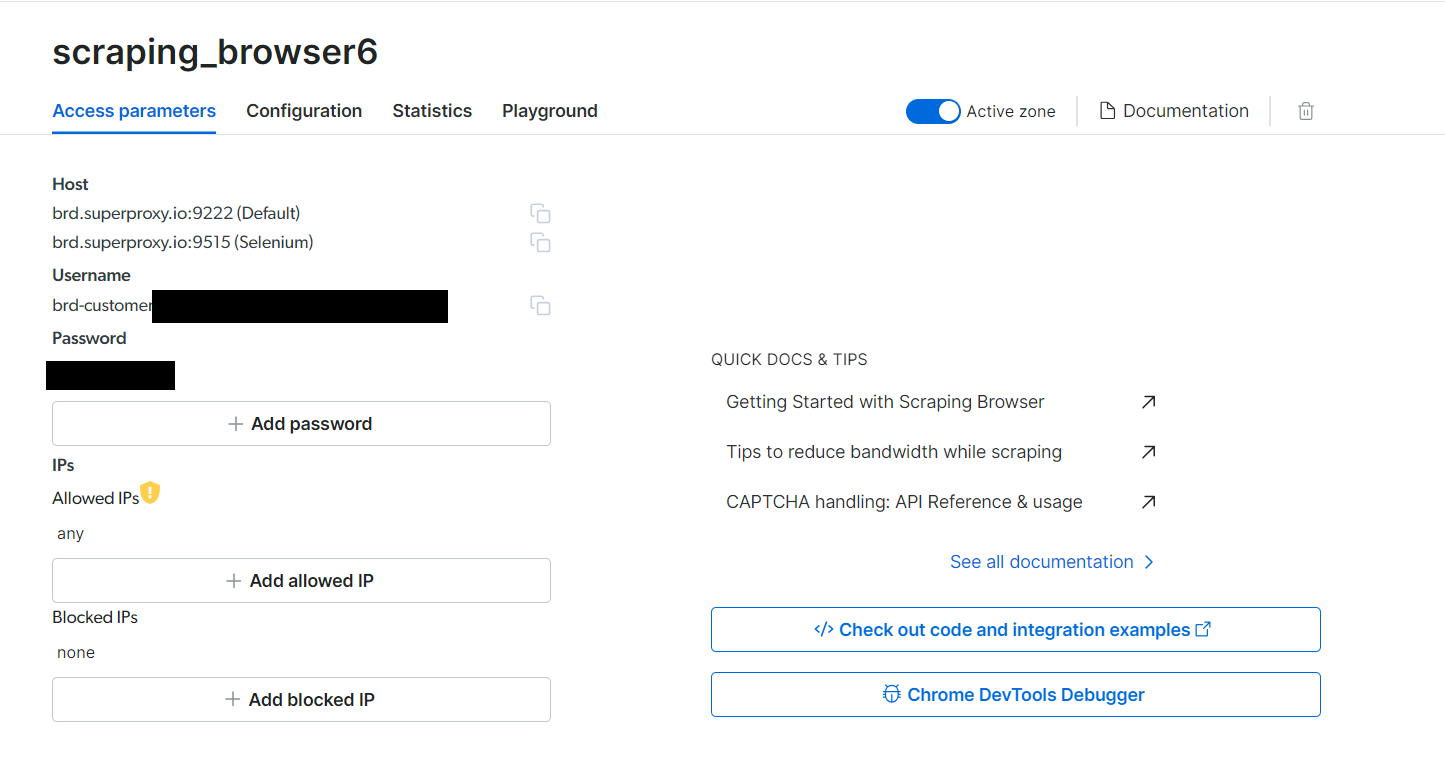
Note down these values, you'll need them later.
Now that we have the necessary keys, we can move forward with setting up our Puppeteer script and integrating it with the Scraping Browser (as a prerequisite for this next step, your computer should already have Node.js and NPM installed on it).
Let's move on.
Implementing The Scraper
First off, install Puppeteer.
npm i puppeteer-core
We'll walk through a practical example of web scraping using Puppeteer to search Amazon (amazon.com) for the highest-rated gaming mouse from all search results for "gaming mouse".
The process of navigating the Amazon website for search results and product listings like this is bound to run into anti-bot detection measures CAPTCHAs, and various other blocking mechanisms, but we'll sidestep all of it using Bright Data's Scraping Browser.
Let's start with our script. Import puppeteer-core as usual, then, create an auth string.
const puppeteer = require("puppeteer-core");const auth = "your_username:your_password";
This is the value you copied from the previous step, so just throw it in there as one long string in the format given.
Next, let's actually use the Scraping Browser.
(async () => {
let browser
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`,
})
const page = await browser.newPage()
await page.goto('https://www.amazon.com/s?k=gaming+mouse')
// rest of your scraping logic here
} catch (err) {
// handle error
}
})();
We're using puppeteer.connect to attach our Puppeteer script to an existing, running browser instance --- and we're doing it via WebSockets by passing in the WebSocket URL to Bright Data's servers via the browserWSEndpoint attribute (with the auth string).
Now, you can concentrate solely on your scraping logic, and not worry about handling CAPTCHA, proxy rotation, anti-bot measures, or anything else. Let's move on!
const puppeteer = require('puppeteer-core')
const auth = 'your_username:your_password'
// get highest rated item from list
function getHighestRatedItem(items) {
return items.reduce((highest, current) => {
const currentRating = parseFloat(current.rating.split(' ')[0]) // extract numeric part of rating i.e. 4.5 from '4.5 out of 5 stars'
const highestRating = parseFloat(highest.rating.split(' ')[0])
return currentRating > highestRating ? current : highest
}, items[0])
}
(async () => {
let browser
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`,
})
const page = await browser.newPage()
await page.goto('https://www.amazon.com/s?k=gaming+mouse')
// wait for the search results to be available
await page.waitForSelector("div[class*='s-result-item']")
const data = await page.evaluate(() => {
const elements = document.querySelectorAll('div.s-result-item')
const results = []
elements.forEach((element) => {
// query for item name
const title = element.querySelector('div[data-cy="title-recipe"]')
if (title) {
// query for item price
const price = element.querySelector('div[data-cy="price-recipe"]')
// query for item rating out of 5
const rating = element.querySelector('div[data-cy="reviews-block"] span')
// sanitize
const titleText = title.textContent.trim()
const priceText = price.textContent.trim()
const ratingText = rating ? rating.getAttribute('aria-label').trim() : 'N/A' // set default
// push to results array, get rid of sponsored results
if (!titleText.startsWith('Sponsored')) {
results.push({
item: titleText,
price: priceText.split('$').slice(0, 2).join('$'), // replace with currency of choice instead of USD ($)
rating: ratingText,
})
}
}
})
return results
})
// console.log(data); // log the extracted results, or store wherever.
console.log(getHighestRatedItem(data)) // get highest rated item
await browser.close()
} catch (err) {
console.error('RUN FAILED:', err)
}
})()
The rest of the code is standard fare jQuery/Puppeteer --- we're getting item name, price, and rating via selectors, and using a reduce function to find the highest rated item from among them.
// get highest rated item from list
function getHighestRatedItem(items) {
return items.reduce((highest, current) => {
const currentRating = parseFloat(current.rating.split(' ')[0]) // extract numeric part of rating i.e. 4.5 from '4.5 out of 5 stars'
const highestRating = parseFloat(highest.rating.split(' ')[0])
return currentRating > highestRating ? current : highest
}, items[0])
}
After converting Amazon's rating strings like "4.5 out of 5 stars" to a proper float value first, of course.
The output of this script can be formatted to any format you want, used further, or even stored in a database. For now, though, this is all we'll need for this tutorial.
{
item: 'Logitech G502 HERO High Performance Wired Gaming Mouse, HERO 25K Sensor, 25,600 DPI, RGB, Adjustable Weights, 11 Programmable Buttons, On-Board Memory, PC / Mac',
price: '$34.99',
rating: '4.7 out of 5 stars'
}
Conclusion
This article covered only a single use case of web scraping when it comes to Amazon. There are many other things you could do by collecting data from Amazon, from price monitoring to sentiment analysis. We also looked at some of the challenges faced when trying to scrape Amazon with vanilla JavaScript. The Scraping Browser was able to successfully work around these challenges with our Puppeteer script largely due to the powerful unlocker infrastructure it utilizes.
Thanks to the unlocker infrastructure, complicated tasks like solving CAPTCHAs, bypassing fingerprinting, preventing rate-limits by rotating proxies, and changing the user-agent string are all handled by Bright Data. This allows your code to stay clean and focused solely on retrieving the data you're after.
💡 You can check out the official documentation to learn more about the Scraping Browser and how it can be integrated with other tools like Selenium or Playwright.
It is important to make use of web scraping responsibly, and to also essential to consider the ethical implications and uphold data privacy laws. Bright Data's Scraping Browser excels here too, being compliant with major data protection laws like the GDPR.
Overall, data-rich e-commerce platforms offer a treasure trove of insights that are applicable to many diverse industry use cases. With the Scraping Browser, you can collect this data seamlessly, at scale, with your existing Puppeteer/Selenium/Playwright script without spending sleepless nights over anti-scraping measures.
👉 Sign up for a free trial to experience the power of the Scraping Browser for yourself.
💡 Also note that Bright Data is offering to match up to $500 of your first deposit if you sign up for any of the paid plans.
Comments
Loading comments…