A complete step-by-step guide to scraping job data from Indeed using Python, BeautifulSoup, Selenium, and mobile proxies.

With thousands of jobs posted daily, Indeed has become a leading source of employment data, providing insights into hiring trends, skill demands, and geographic job distribution. For analysts, developers, and job seekers, access to this data can provide insights that drive career decisions and research.
However, collecting this data at scale brings unique challenges: first, manually collecting data from listings would be impractical at scale — this is where web scraping comes in. Secondly, Indeed’s advanced site protections and automation limits make it difficult to extract information without getting blocked. In this article, you will learn how to handle these challenges using Python, proxies, and other web scraping tools and successfully extract data from Indeed.
Prerequisites
Before beginning this tutorial, ensure you meet the following requirements:
Skills Needed:
- Basic knowledge of Python programming.
- Familiarity with the BeautifulSoup, Selenium and, pandas libraries.
Setup Steps:
- Install Python: If you haven’t already, download and install Python.
- Set Up a Virtual Environment: Run the following command in your terminal to create a virtual environment:
python3 -m venv myenv
- Next, Activate the Virtual Environment:
On Windows:
myenvScriptsactivate
On macOS/Linux:
source myenv/bin/activate
- Install Required Libraries: Once the virtual environment is activated, install the necessary libraries by running:
pip install pandas selenium bs4
- Create a Python File for the Script:
In your project directory, create a new Python file where you’ll write the scraping script. Use the following command to create and open a file named scrape.py:
touch scrape.py
(On Windows, you can use notepad scrape.py or open the file with your preferred editor.)
Step 1: Setting up Bright Data Proxy
To extract data from Indeed, you need to bypass the site’s anti-bot protection. Indeed employs advanced security measures that can block scripts attempting to access job listings.
Indeed.com
However, to bypass these challenges, you will need to integrate a proxy in your script. This article uses Bright Data’s mobile proxies, which you can trial for free.
Getting Started with Bright Data’s Mobile Proxies
Follow these steps to set up your Bright Data mobile proxy:
- Sign up for Bright Data: If you haven’t already, you can sign up for Bright Data for free. Adding a payment method will also give you a $5 credit.
- After logging in, click on “Get Proxy Products”.
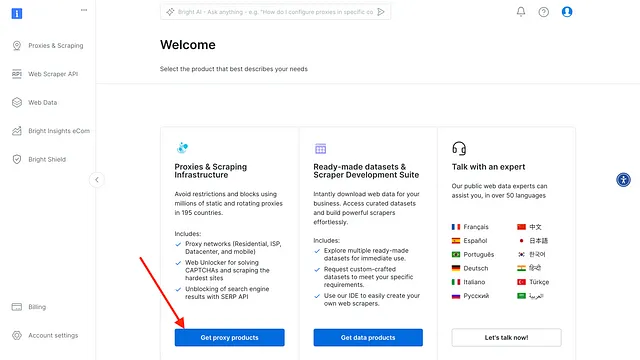
- Click on “Add” and select “Mobile proxies”
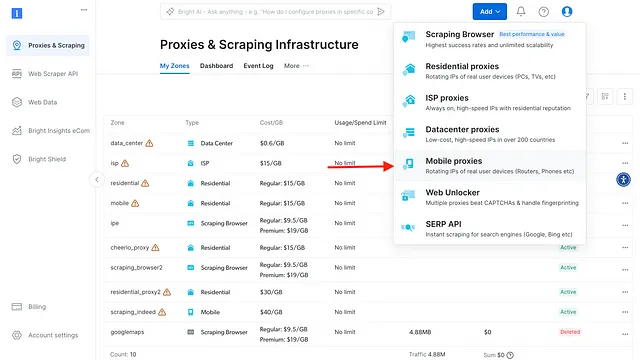
- Enter the Proxy name for your new Mobile proxy, then click “Add”
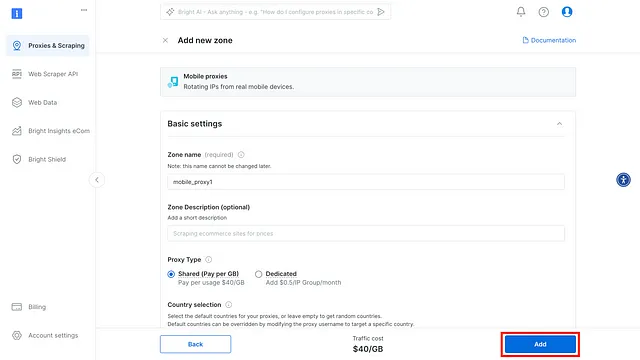
- After this, your mobile proxy zone credentials will be created, which includes
host,username, andpassword. You will need these details in your script to bypass any anti-scraping mechanisms used on any website.
Bright Data Mobile Proxy
Step 2: Understanding Indeed’s website structure
Before diving into web scraping, it’s essential to understand how Indeed organizes job listing data on its site. Examining the website’s structure will help us identify the HTML elements that hold relevant job information, such as job titles, company names, locations, descriptions, and job URLs. By doing so, you can design a scraping script that reliably extracts this data.
Analyzing the HTML Layout
When you open a search results page on Indeed, use your browser’s Inspect tool to examine its HTML. Right-click on a job listing and select Inspect (or use Ctrl+Shift+I on most browsers) to view the page’s HTML structure.
Key elements to look for include:
- Job Titles: Located within
<h2>tags with a specific class ofjobTitle. - Company Names: found inside
<span>tags withdata-testid=”company-name”. - Locations: It appears within
<div>tags that use thedata-testid=”text-location”attribute. - Job Descriptions: Found within a
<div>tags with the following classes:heading6 tapItem-gutter css-1rgici5 eu4oa1w0 - Job Links: Found in an anchor tag
<a>with classes ofjcs-JobTitle css-1baag51 eu4oa1w0.
By inspecting these elements, you can confirm the unique HTML structure Indeed uses to display job data. Note these classes and attributes; they’ll be crucial when you write the scraping code.
Identifying Pagination
To efficiently scrape data from multiple pages on Indeed, you need to identify how pagination works on the website. Pagination allows users to navigate between pages of job listings, typically by clicking “Next” or selecting a specific page number. For your scraper to gather all available listings, it must simulate these actions.
On Indeed’s job listings page, the pagination section is structured as a navigation element (<nav>) with multiple list items (<li>) representing the different pages. Each page link has a unique href attribute with a start parameter that increments with each page (e.g., start=10, start=20). The “Next” button is also a part of this navigation and can be selected using its data-testid=”pagination-page-next” attribute.
Having this understanding of Indeed’s structure enables you to target relevant data elements and navigate through paginated results efficiently. In the next step, we’ll start implementing these insights by writing code to capture job data.
Step 3: Scraping Data from Indeed Job Listings
In this step, you’ll use the Python script (scrape.py) to extract job data from Indeed. The script gathers job titles, company names, locations, descriptions, and URLs from a search results page. Follow the steps below to set up and execute the script. ( you can find the complete code for this tutorial here on GitHub.)
- Import the Required Libraries: Begin by importing the necessary Python libraries into your script:
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
import time
These libraries enable web scraping, dynamic content rendering, and data manipulation.
- Configure the Proxy and WebDriver: To bypass potential scraping restrictions, configure a proxy. This example uses Bright Data Mobile Proxy:
# Bright Data Mobile Proxy credentials
proxy_host = "your_proxy_host"
proxy_port = "your_proxy_port"
proxy_user = "your_proxy_username"
proxy_pass = "your_proxy_password"
# Configure Chrome options with proxy
chrome_options = Options()
chrome_options.add_argument("--headless") # Optional: Run browser in headless mode
chrome_options.add_argument(f"--proxy-server=http://{proxy_user}:{proxy_pass}@{proxy_host}:{proxy_port}")
# Initialize the web driver with proxy configuration
driver = webdriver.Chrome(options=chrome_options)
- Define the target URL: Set the URL of the Indeed job search page you want to scrape. Replace the query parameters (q and l) with your desired job title and location.
url = 'https://www.indeed.com/jobs?q=web+developer&l=New+York%2C+NY'
- Prepare Storage for Scraped Data: Initialize lists to store the extracted data:
# Lists to store scraped data
titles = []
companies = []
locations = []
descriptions = []
urls = []
Scraping job listings from the current page: Define a function to extract job details from the current page:
# Function to scrape job listings on the current page
def scrape_current_page():
try:
# Wait until at least one job posting is present on the page
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.CLASS_NAME, 'jobTitle'))
)
except Exception as e:
print("Failed to load job listings:", e)
return # Skip this page if it doesn't load in time
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Extract job details
job_titles = soup.find_all('h2', class_='jobTitle')
company_names = soup.find_all('span', attrs={"data-testid": "company-name"})
job_locations = soup.find_all('div', attrs={"data-testid": "text-location"})
job_descriptions = soup.find_all('div', class_='heading6 tapItem-gutter css-1rgici5 eu4oa1w0')
job_links = soup.find_all('a', class_='jcs-JobTitle css-1baag51 eu4oa1w0')
# Store data in lists
for i in range(max(len(job_titles), len(company_names), len(job_locations), len(job_descriptions))):
titles.append(job_titles[i].text.strip() if i < len(job_titles) else "N/A")
companies.append(company_names[i].text.strip() if i < len(company_names) else "N/A")
locations.append(job_locations[i].text.strip() if i < len(job_locations) else "N/A")
# Job description processing
if i < len(job_descriptions):
description = job_descriptions[i].find_all('li')
desc_text = [li.text.strip() for li in description]
descriptions.append('; '.join(desc_text) if desc_text else "N/A")
else:
descriptions.append("N/A")
# Job link processing
if i < len(job_links):
job_url = 'https://www.indeed.com' + job_links[i]['href'] # Append the Indeed base URL
urls.append(job_url)
else:
urls.append("N/A")
- Saving data to a CSV file: Finally, save the extracted data to a CSV file using Pandas:
# Create DataFrame and save to CSV
df = pd.DataFrame({
'Title': titles,
'Company': companies,
'Location': locations,
'Description': descriptions,
'URL': urls
})
df.to_csv('indeed_jobs.csv', index=False)
This generates a CSV file (indeed_jobs.csv) with the scraped data.
You have successfully extracted data from Indeed. However, without handling pagination, you will only be able to access the few job data on the first page and will not be able to access job data on other pages. In the next section, you will see how to fix that.
Step 4: Handling Pagination
When scraping job listings from websites like Indeed, data often spans multiple pages. To ensure comprehensive data collection, implement a pagination loop to navigate through all available pages.
The following code iterates through all pages of job listings, scraping data from each page and navigating to the next one:
# Open the starting URL
driver.get(url)
# Pagination loop
while True:
scrape_current_page() # Scrape the current page
# Check if the "Next" button exists and click it
try:
next_button = driver.find_element(By.CSS_SELECTOR, 'a[data-testid="pagination-page-next"]')
driver.execute_script("arguments[0].click();", next_button) # Click the "Next" button
time.sleep(3) # Pause to allow the next page to load
except Exception as e:
print("No more pages to navigate:", e)
break # Break the loop if no "Next" button is found
Step-by-Step Explanation
- Start with the Target URL: The script begins by loading the first page of job listings using the
driver.get(url)command. - Scrape the Current Page: Call the
scrape_current_page()function to extract job details from the current page. - Locate the “Next” Button: Use
driver.find_elementwith the appropriate CSS selector (‘a[data-testid=”pagination-page-next”]’) to identify the “Next” button. - Navigate to the Next Page: Use
driver.execute_scriptto simulate a click on the “Next” button. Adding a brief delay (time.sleep(3)) ensures the next page loads completely before the loop continues. - Handle End of Pagination: If the “Next” button is absent or an error occurs, the script prints a message (
“No more pages to navigate”) and exits the loop.
With that, you will be able to scrape all the job data available for that job search; now, instead of just 15 job data, you get 391 job data extracted successfully.
Scraped data from Indeed
Conclusion
Scraping job listings from websites like Indeed is a valuable way to gather data for market analysis, job trends, or research. This article guided you through setting up a Python script to scrape job titles, companies, locations, descriptions, and URLs efficiently.
However, successfully navigating the complexities of web scraping often requires tools that can bypass IP restrictions and CAPTCHA challenges. This is where proxies play a critical role. By routing your requests through a proxy network, you can avoid being blocked, ensure anonymity, and scale your data collection efforts seamlessly.
If you’re looking for a reliable and robust proxy solution, consider Bright Data’s proxies. With their extensive network of mobile, residential, and data centre proxies, Bright Data ensures your scraping projects run smoothly, securely, and without interruptions.
Comments
Loading comments…