Effortlessly Extract Google Maps Reviews Using Puppeteer and Bright Data's Scraping Browser: A Step-by-Step Guide for Scalable Data Collection

How to scrape reviews from Google Maps
Google Maps is a goldmine of user-generated reviews, providing insights that can drive better decision-making for businesses, market analysts, and developers. From understanding customer sentiment to identifying trends, reviews on Google Maps can reveal valuable information about customer preferences, service quality, and local competition.
However, Google Maps has anti-scraping mechanisms in place to prevent the extraction of data. This guide will walk you through scraping Google Maps reviews and how to leverage Bright Data's scraping browser to collect review data effectively without being blocked.
Understanding Google Maps Reviews Data
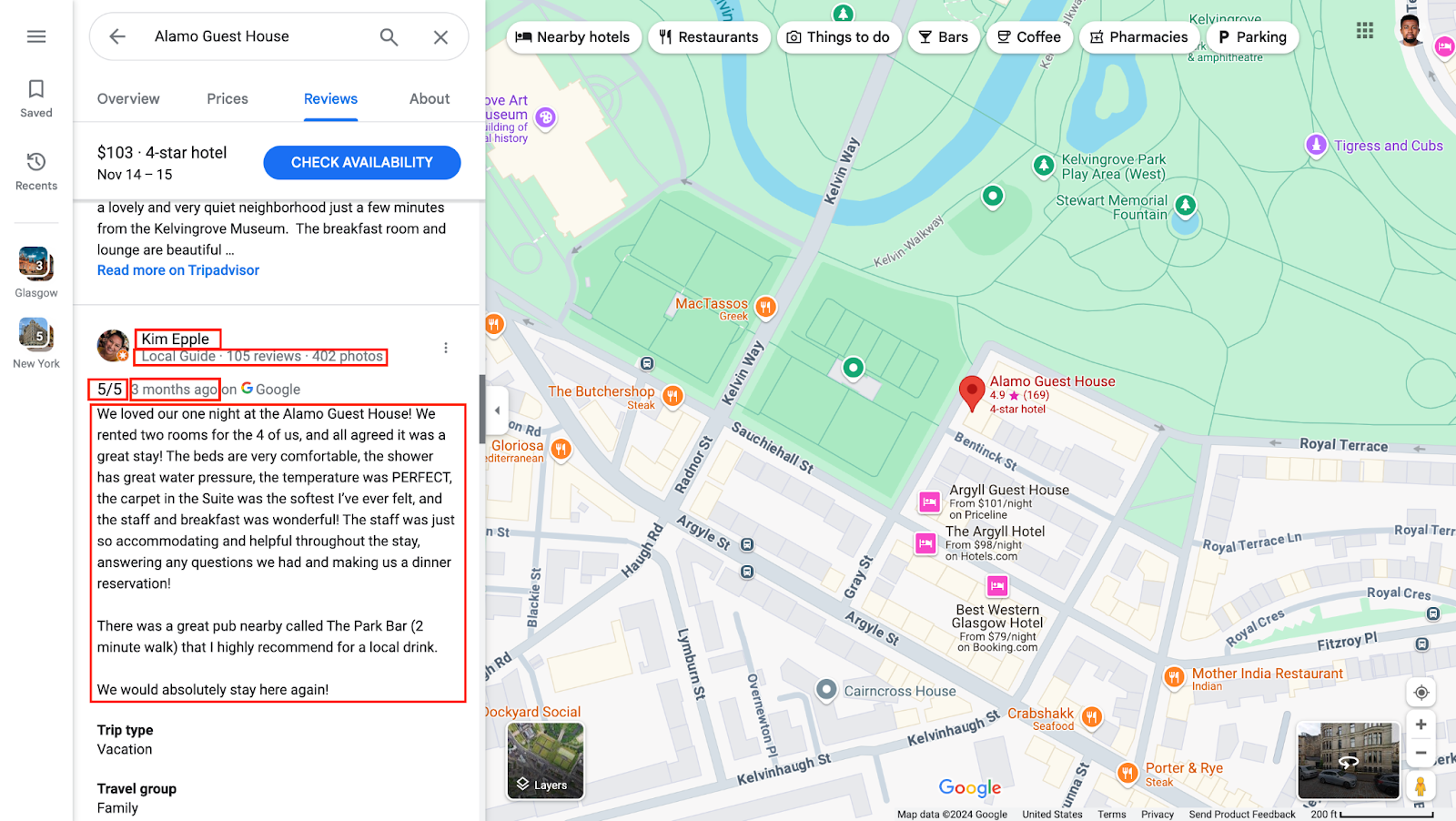
Google Maps
Each review contains multiple data points, including:
- Reviewer Name: Identifies the individual who wrote the review, providing authenticity and a personal touch.
- Rating: Typically given as a star rating, this numerical data point quickly indicates customer satisfaction. When averaged across all reviews, ratings can reveal an overall sentiment for a business.
- Review Text: The most detailed part of the review, this is where customers share their experiences, feedback, and opinions in their own words, often mentioning specific aspects of their experience (e.g., service quality, product satisfaction).
- Date of Review: Time-stamping each review is important for trend analysis. Newer reviews often reflect a business's current state, while older ones can give historical insights.
When scraping this data, it's important to be aware of some potential limitations and challenges:
- Dynamic Content and Lazy Loading: Google Maps often uses JavaScript to load reviews dynamically as users scroll. This technique can make scraping more complex since the review data may not load until a user (or automated bot) interacts with the page.
- Rate Limits and Anti-Scraping Measures: Google's servers are designed to detect and block high-frequency requests from the same IP address, which is why rotating proxies (like those provided by Bright Data) are essential for maintaining continuous access.
- Data Structure and HTML Parsing: Reviews on Google Maps are embedded in a complex HTML structure, with various elements and classes specific to different parts of the review (e.g.,
class="review",class="author", etc.). Locating and isolating these elements is a necessary step for successful data extraction.
To handle these issues, you will leverage the Scraping Browser in your script. The Bright Data Scraping Browser is an automated, headfull browser designed to simplify scraping complex websites with anti-bot measures, dynamic content, and CAPTCHAs.
Unlike typical browsers used in automation tools like Puppeteer or Playwright, Scraping Browser has built-in unblocking features that handle CAPTCHA solving, browser fingerprinting, retries, and JavaScript rendering. With a massive pool of residential IPs and automated proxy rotation, it mimics real user behaviour to bypass website restrictions efficiently, allowing you to focus on data extraction without extensive configuration.
Identifying target elements on Google Maps
To scrape reviews from Google Maps, the first step is to identify the HTML elements containing the data you need. Since Google Maps loads content dynamically and uses complex HTML structures, understanding how to locate these elements efficiently will simplify your scraping process.
1. Inspecting Google Maps Elements
- Open Google Maps in Developer Tools: Go to Google Maps in Chrome, right-click on the page, and select "Inspect" to open Developer Tools. Navigate to a business listing with reviews to examine how the page structures its elements.
- Locate Reviews Section: In Developer Tools, scroll to the reviews section of the page and use the "Select Element" tool to pinpoint specific review components (review text, rating, reviewer name, date, etc.).
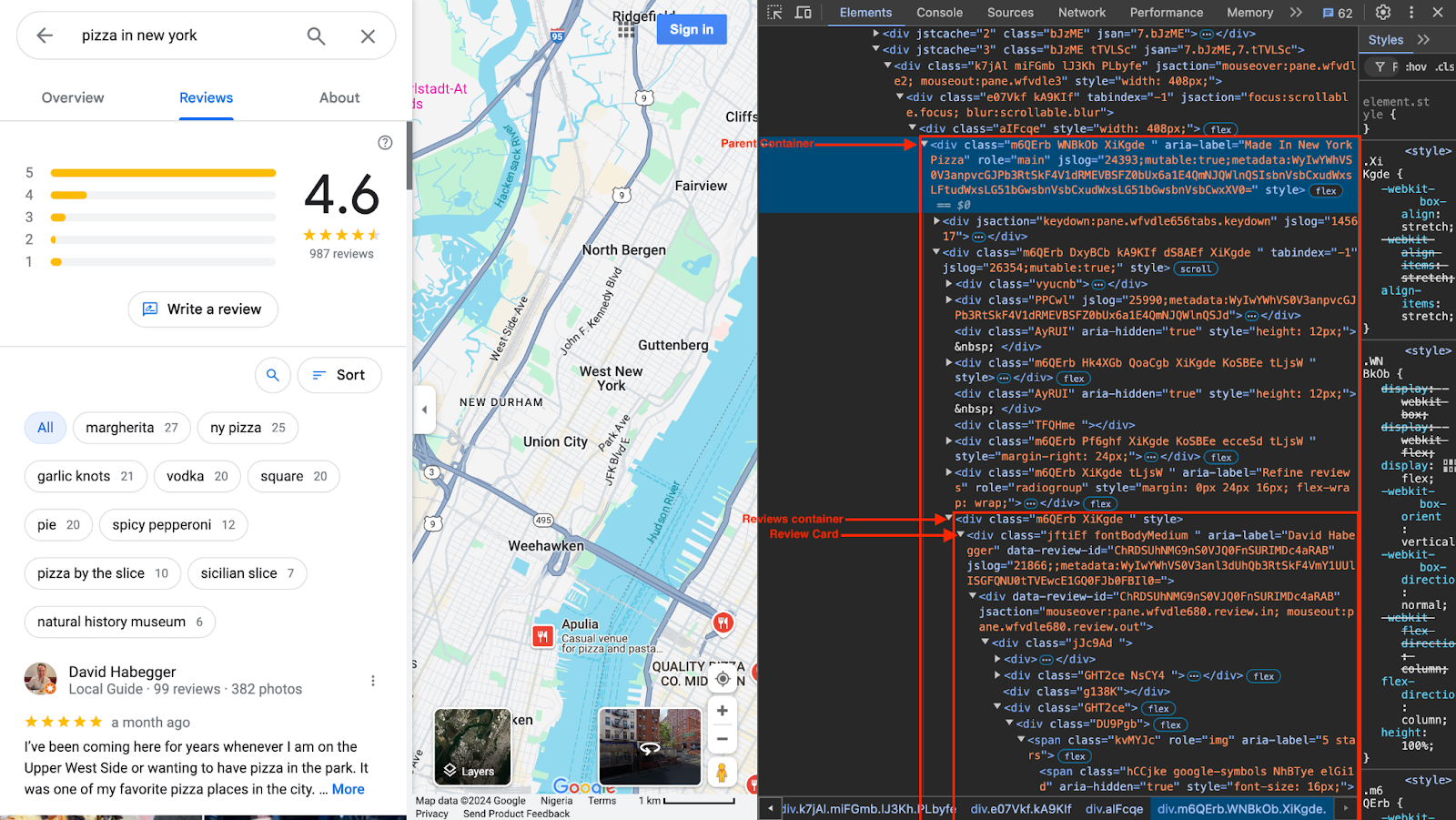
Google Maps in Developer Tools
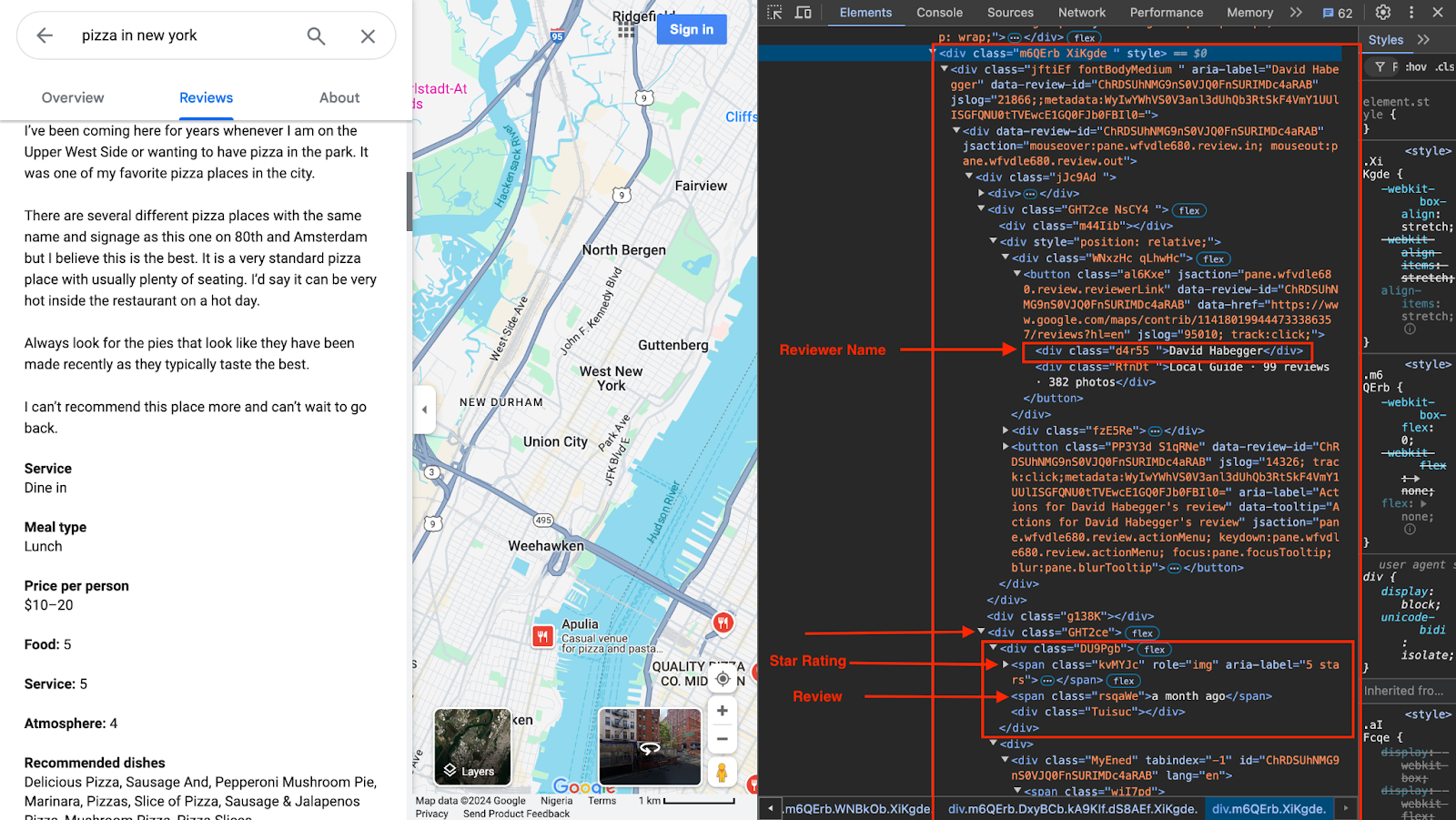
Google Maps in Developer Tools
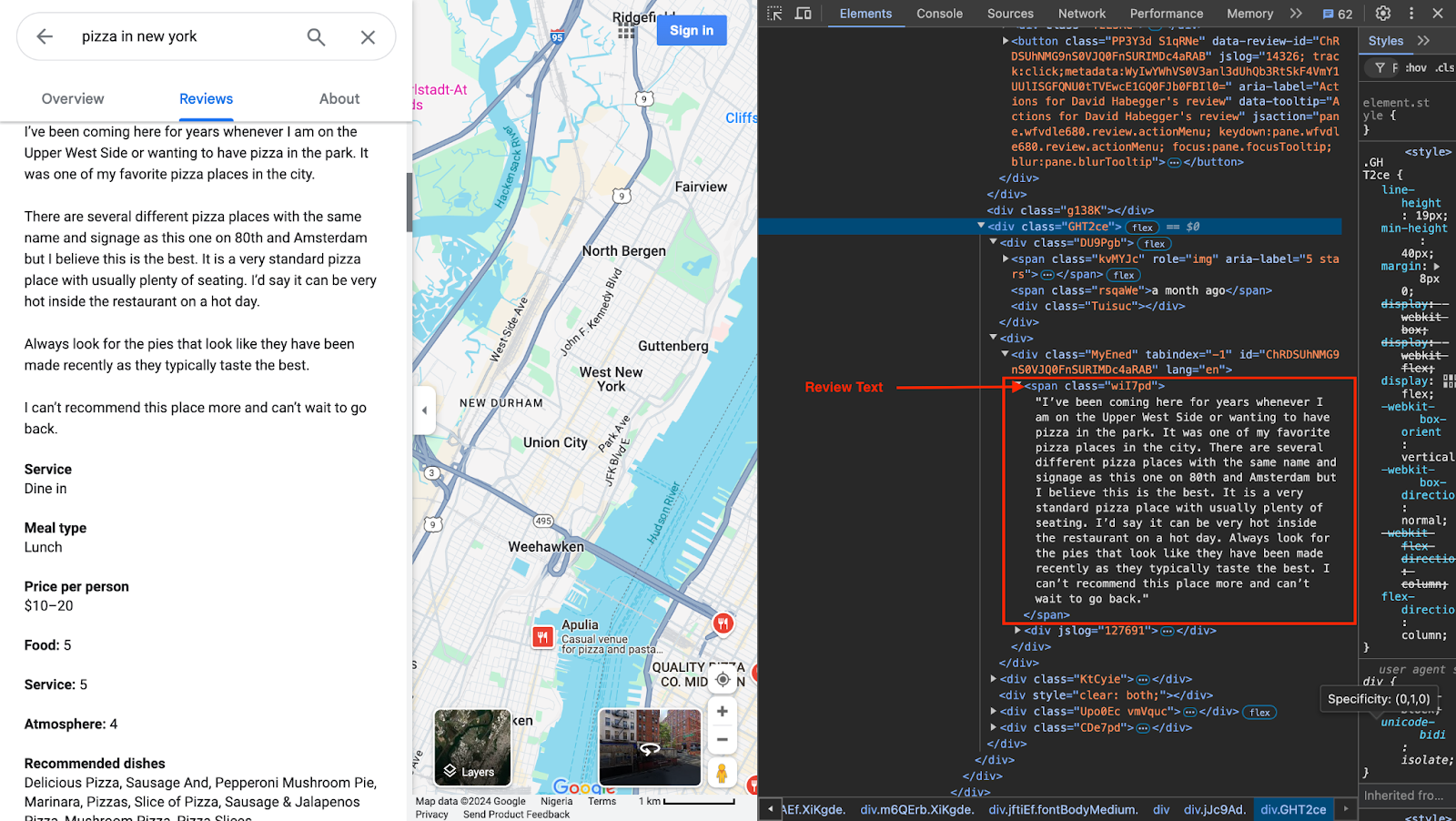
Google Maps in Developer Tools
2. Target Elements for Data Extraction
As seen in the images above, the following are the key elements you need to target to extract the reviews:
- Parent Container: From inspecting the web page, you can see that the parent container is a
divwith a.WNBkObclass. - Review container: The reviews are enclosed in a
divelement with a.XiKgdeclass - Review card: The review is in a
divcard with a.jftiEf.fontBodyMediumclass - Review text: The review text is enclosed in a
spanelement with a.wiI7pdclass. - Reviewer name: The reviewer's name is stored in a
divelement with a.d4r55class name. - Star rating: The stars are in a
spanelement with a.kvMYJcclass name. - Review date: The date is in a
spanelement with a.rsqaWeclass name
Step-by-step guide to scraping reviews from Google Maps
This section will walk you through each step, including setting up your environment, configuring the scraping browser and writing the Puppeteer script to collect the review data.
Setting up the environment
To scrape Google Maps reviews effectively, we'll be using Node.js and Puppeteer, a powerful headless browser automation library that makes it easy to interact with web pages. Puppeteer allows us to load Google Maps, scroll through dynamically loaded reviews, and extract the necessary data. Here's a step-by-step guide to setting up the environment:
1. Install Node.js and NPM
- Ensure that Node.js and npm (Node Package Manager) are installed on your machine. If they aren't, download the latest version from the official Node.js website.
- To check if they're already installed, run:
node -v
npm -v
2. Create a project directory and initialize NPM
- Create a new directory for the project and initialize it with npm:
mkdir google-maps-scraper
cd google-maps-scraper
npm init -y
- This command creates a
package.jsonfile where all project dependencies will be listed.
3. Install Puppeteer
- Puppeteer can be installed via npm. This package includes a recent version of Chromium, which Puppeteer controls under the hood:
npm install puppeteer
Setting your Scraping Browser
Generate the credentials (Host, Username and Password) of the scraping browser that will be incorporated into the script for uninterrupted data extraction. You can do that by following these steps:
- Signing up - go to Bright Data's homepage and click on "Start Free Trial". If you already have an account with Bright Data, you can just log in.
- After logging in, click on "Get Proxy Products".
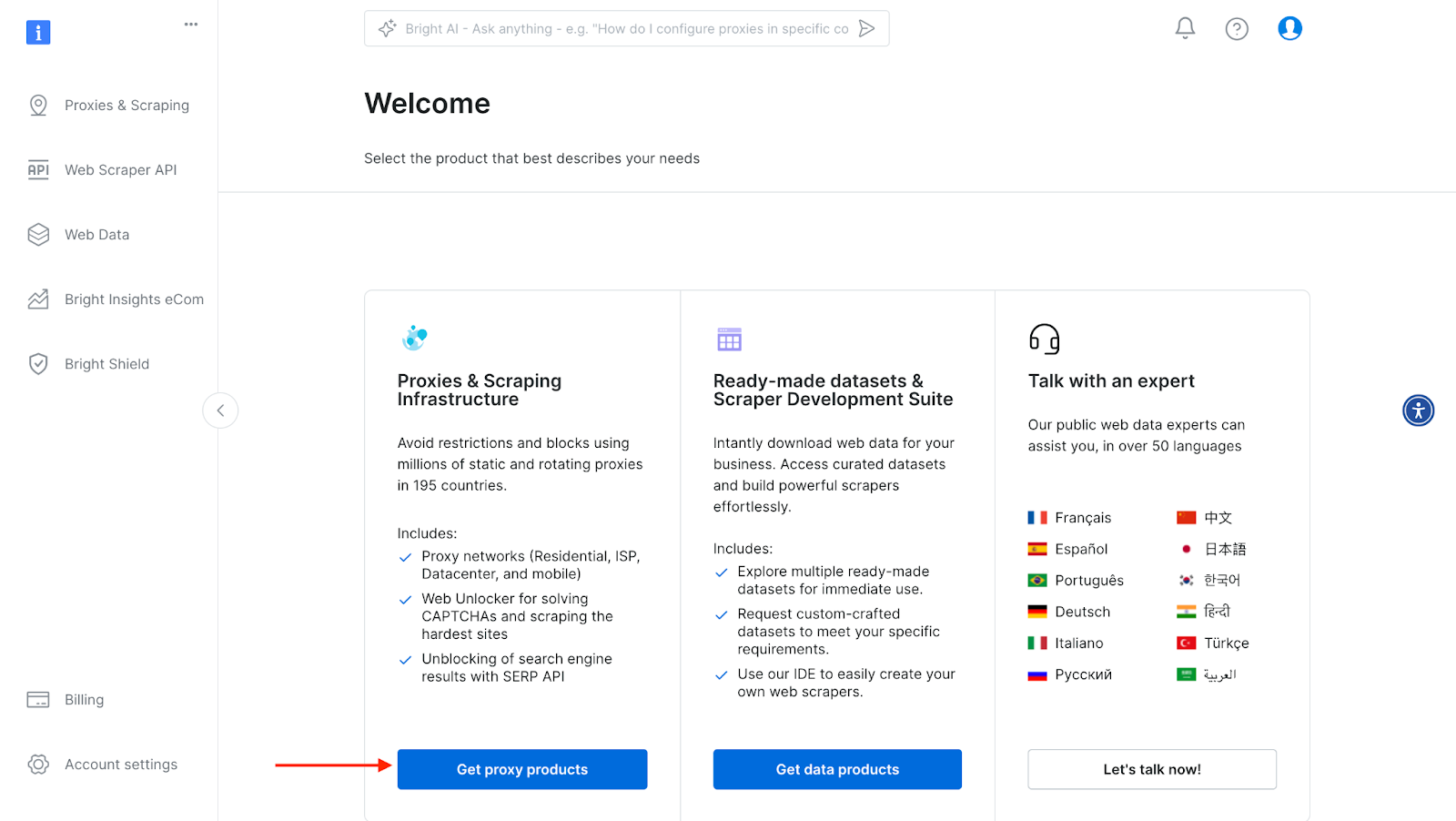
Bright Data Scraping Browser
- Click on the "Add" button and select "Scraping Browser."
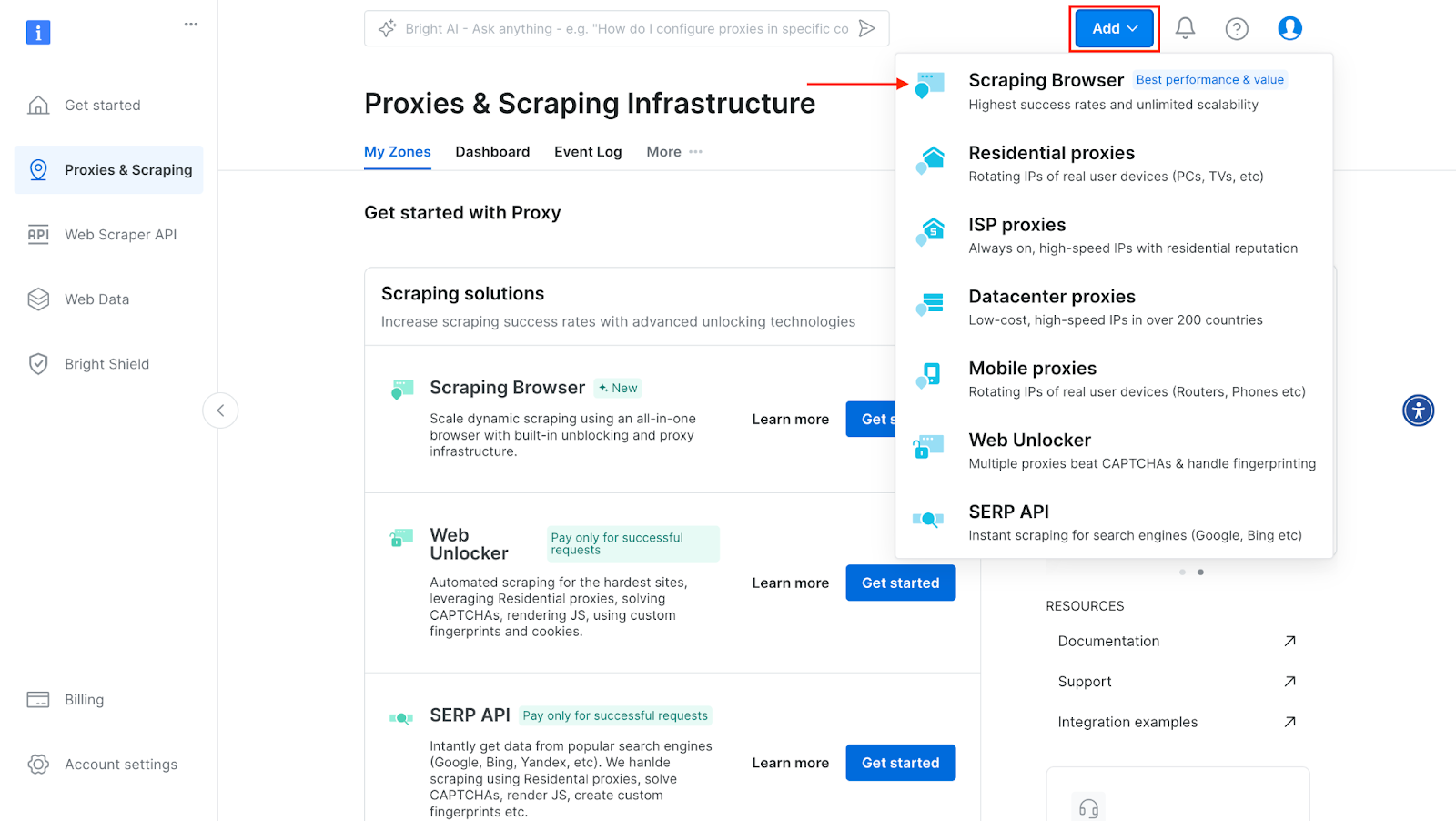
Bright Data Scraping Browser
- Next, you will be taken to the "Add zone" page, where you will be required to choose a name for your new scraping browser proxy zone. After that, click on "Add".
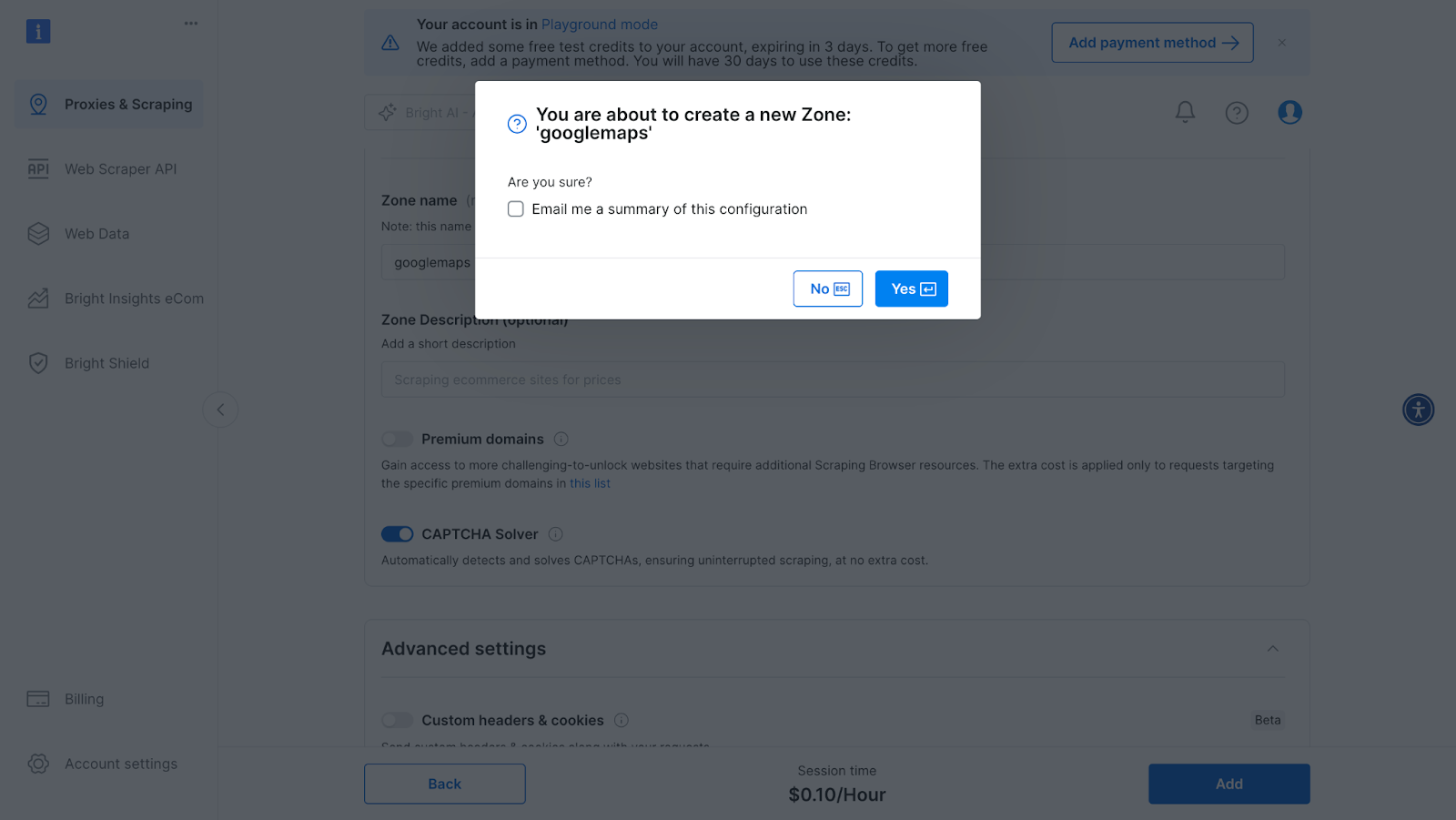
Bright Data Scraping Browser
- After this, your proxy zone credentials will be created. You will need this detials in your script, to bypass any anti-scraping mechanisms used on any website.
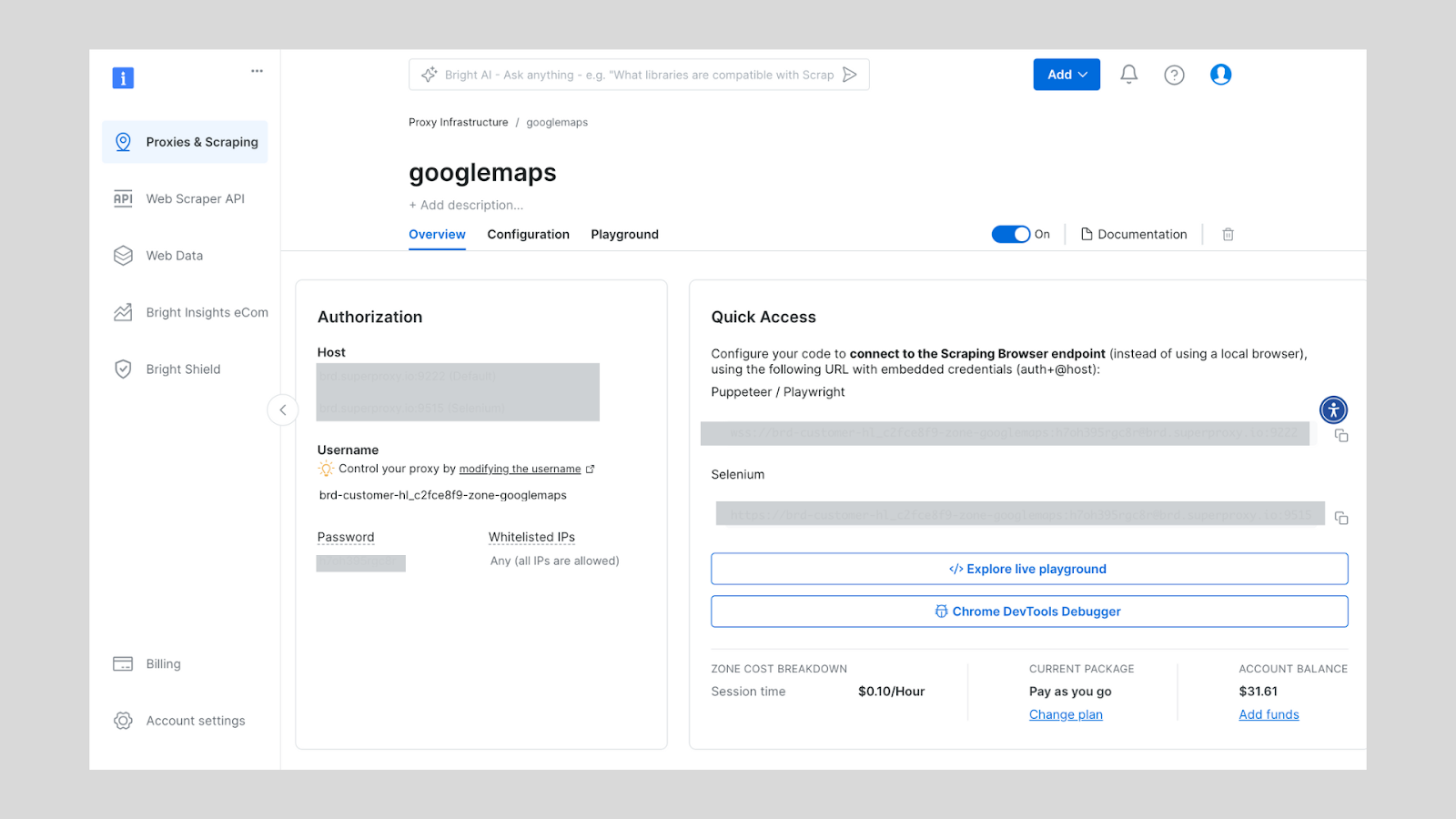
Bright Data Scraping Browser
You can also check out Bright Data's developer documentation for more details about the scraping browser.
NodeJS script to scrape Google Maps
Now that the environment is ready, create a JavaScript file, e.g., scrape.js, where you'll write the main Puppeteer script to access Google Maps, handle dynamic loading, and extract reviews.
const puppeteer = require('puppeteer')
;(async () => {
try {
const url =
'https://www.google.com/maps/place/Made+In+New+York+Pizza/@40.7838392,-74.0537874,13z/data=!4m13!1m3!2m2!1spizza+in+new+york!6e5!3m8!1s0x89c259ddd4cde22f:0xdc61ba2b00a3adf0!8m2!3d40.7838392!4d-73.9775697!9m1!1b1!15sChFwaXp6YSBpbiBuZXcgeW9ya1oTIhFwaXp6YSBpbiBuZXcgeW9ya5IBEHBpenphX3Jlc3RhdXJhbnTgAQA!16s%2Fg%2F11n8ng0xxw?entry=ttu&g_ep=EgoyMDI0MTExMC4wIKXMDSoASAFQAw%3D%3D'
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
// Set proxy authentication
await page.authenticate({
username: '<paste your proxy username here>',
password: '<paste your proxy password here>',
host: '<paste your proxy host here>',
})
await page.setViewport({ width: 1920, height: 1080 })
console.log('Navigating to page...')
await page.goto(url, { waitUntil: 'networkidle2', timeout: 60000 })
// Wait for reviews to load
console.log('Waiting for reviews to load...')
try {
await page.waitForSelector('.jftiEf.fontBodyMedium', { timeout: 10000 })
} catch (error) {
console.error('Could not find any reviews on the page')
await browser.close()
return
}
console.log('Starting to scroll for reviews...')
const totalReviews = await page
console.log(`Finished scrolling. Found ${totalReviews} reviews.`)
const reviews = await page.evaluate(() => {
const reviewCards = document.querySelectorAll('.jftiEf.fontBodyMedium')
const reviewData = []
reviewCards.forEach((card) => {
const reviewerName = card.querySelector('.d4r55')?.innerText || null
const reviewText = card.querySelector('.wiI7pd')?.innerText || 'No review content'
const reviewDate = card.querySelector('.rsqaWe')?.innerText || null
const starRatingElement = card.querySelector('.kvMYJc')
let starRating = 0
if (starRatingElement && starRatingElement.getAttribute('aria-label')) {
const ratingText = starRatingElement.getAttribute('aria-label')
const match = ratingText.match(/(d+)s+stars/)
if (match && match[1]) {
starRating = parseInt(match[1], 10)
}
}
reviewData.push({
reviewerName,
reviewText,
reviewDate,
starRating,
})
})
return reviewData
})
console.log(`Successfully extracted ${reviews.length} reviews`)
// Output reviews as JSON in the terminal
console.log(JSON.stringify(reviews, null, 2))
await browser.close()
} catch (error) {
console.error('An error occurred:', error)
}
})()
Code Explanation
- Setting Up Puppeteer:
- The script uses Puppeteer, a Node.js library, to control a headless browser. It opens with
const puppeteer = require('puppeteer');and an asynchronous function to manage the browser operations.
- URL Configuration:
- The
urlvariable is set to a specific Google Maps link for "Made in New York Pizza." This URL will direct the browser to this page, where the reviews will be extracted.
- Launching the Browser and Setting Proxy:
i. The browser is launched with await puppeteer.launch({ headless: false }), which opens a visible browser for debugging (headless: false). A new page (tab) is created with const page = await browser.newPage().
ii**. Proxy Authentication**:
- The script uses a proxy to access Google Maps through the line:
await page.authenticate({
username: 'your-proxy-username',
password: 'your-proxy-password',
host: 'your-proxy-host:port',
})
- This allows access through a proxy server, so replace the username, password, and host with your scraping browser details.
- Setting the Viewport:
- The viewport (browser window size) is set to
1920 x 1080pixels for better page rendering and element visibility.
- Navigating to the Google Maps Page:
- Using
await page.goto(url, { waitUntil: 'networkidle2', timeout: 60000 });, the script navigates to the URL and waits for the network to be idle, ensuring that the page fully loads before proceeding.
- Waiting for Reviews to Load:
- To scrape reviews, the script waits for the review elements to load with
await page.waitForSelector('.jftiEf.fontBodyMedium'), ensuring the page is ready for data extraction.
- Closing the Browser:
- The script closes the browser using
await browser.close()to end the session, freeing up resources.
However, since there wasn't an auto-scroll function in the script, you will only get 8--9 reviews.
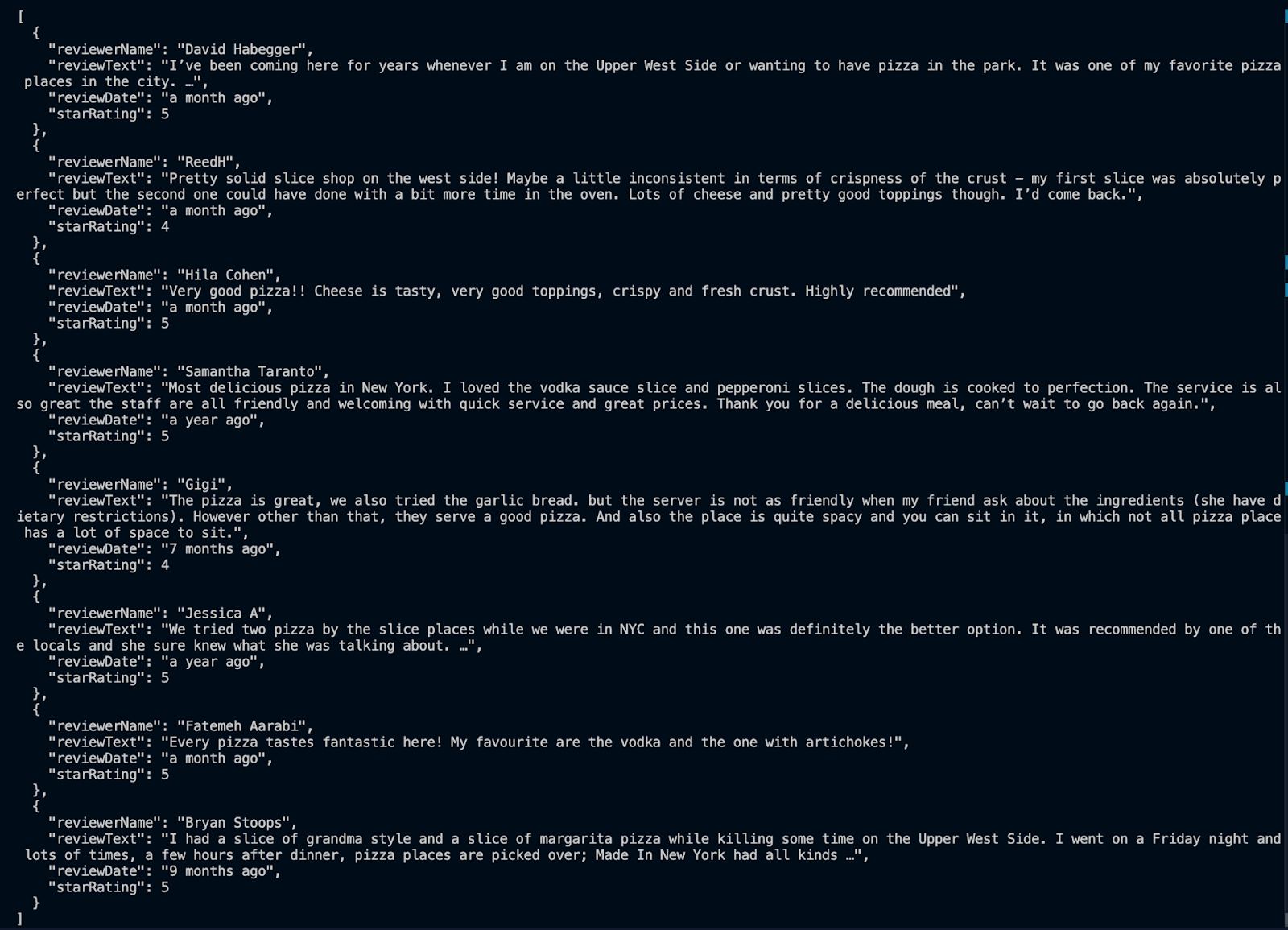
Extracted data from Google Maps
Extracting more reviews using the auto-scroll function
If you want to scrape many reviews, you'll need to include an auto-scroll function in your script. Here's how to auto-scroll and extract data:
async function autoScroll(page) {
return page.evaluate(async () => {
async function getScrollableElement() {
const selectors = [
'.DxyBCb [role="main"]',
'.WNBkOb [role="main"]',
'.review-dialog-list',
'.section-layout-root',
]
for (const selector of selectors) {
const element = document.querySelector(selector)
if (element) return element
}
const possibleContainers = document.querySelectorAll('div')
for (const container of possibleContainers) {
if (
container.scrollHeight > container.clientHeight &&
container.querySelector('.jftiEf.fontBodyMedium')
) {
return container
}
}
return null
}
const scrollable = await getScrollableElement()
if (!scrollable) {
console.error('Could not find scrollable container')
return 0
}
const getScrollHeight = () => {
const reviews = document.querySelectorAll('.jftiEf.fontBodyMedium')
return reviews.length
}
let lastHeight = getScrollHeight()
let noChangeCount = 0
const maxTries = 10
while (noChangeCount < maxTries) {
if (scrollable.scrollTo) {
scrollable.scrollTo(0, scrollable.scrollHeight)
} else {
scrollable.scrollTop = scrollable.scrollHeight
}
await new Promise((resolve) => setTimeout(resolve, 2000))
const newHeight = getScrollHeight()
if (newHeight === lastHeight) {
noChangeCount++
} else {
noChangeCount = 0
lastHeight = newHeight
}
}
return lastHeight
})
}
//The rest of the code remains the same; only change this line below
const totalReviews = await autoScroll(page);
When you run the code, you should be able to extract over 300 reviews instead of the 8 reviews gotten initially.
Data Storage and Export
After scraping, store the review data in a CSV file for further analysis. To do that, you need to make additions to your script.
// Function to create CSV string from reviews
function createCsvString(reviews) {
const headers = ['Reviewer Name', 'Review Text', 'Review Date', 'Star Rating']
const csvRows = [headers]
reviews.forEach((review) => {
// Clean up review text: remove newlines and commas
const cleanReviewText = review.reviewText
.replace(/n/g, ' ') // Replace newlines with spaces
.replace(/,/g, ';') // Replace commas with semicolons
csvRows.push([
review.reviewerName || '',
cleanReviewText || '',
review.reviewDate || '',
review.starRating || '',
])
})
return csvRows.map((row) => row.join(',')).join('n')
}
(async () => {
// ....paste the rest of the code here
// Create CSV string
const csvString = createCsvString(reviews);
// Generate filename with timestamp
const timestamp = new Date().toISOString().replace(/[:.]/g, '-');
const filename = `googlemapsreviews_${timestamp}.csv`;
// Save to file
fs.writeFileSync(filename, csvString);
console.log(`Reviews saved to ${filename}`);
await browser.close();
} catch (error) {
console.error('An error occurred:', error);
}
})();
This step saves the extracted review data in CSV format, which can be opened in an Excel sheet.
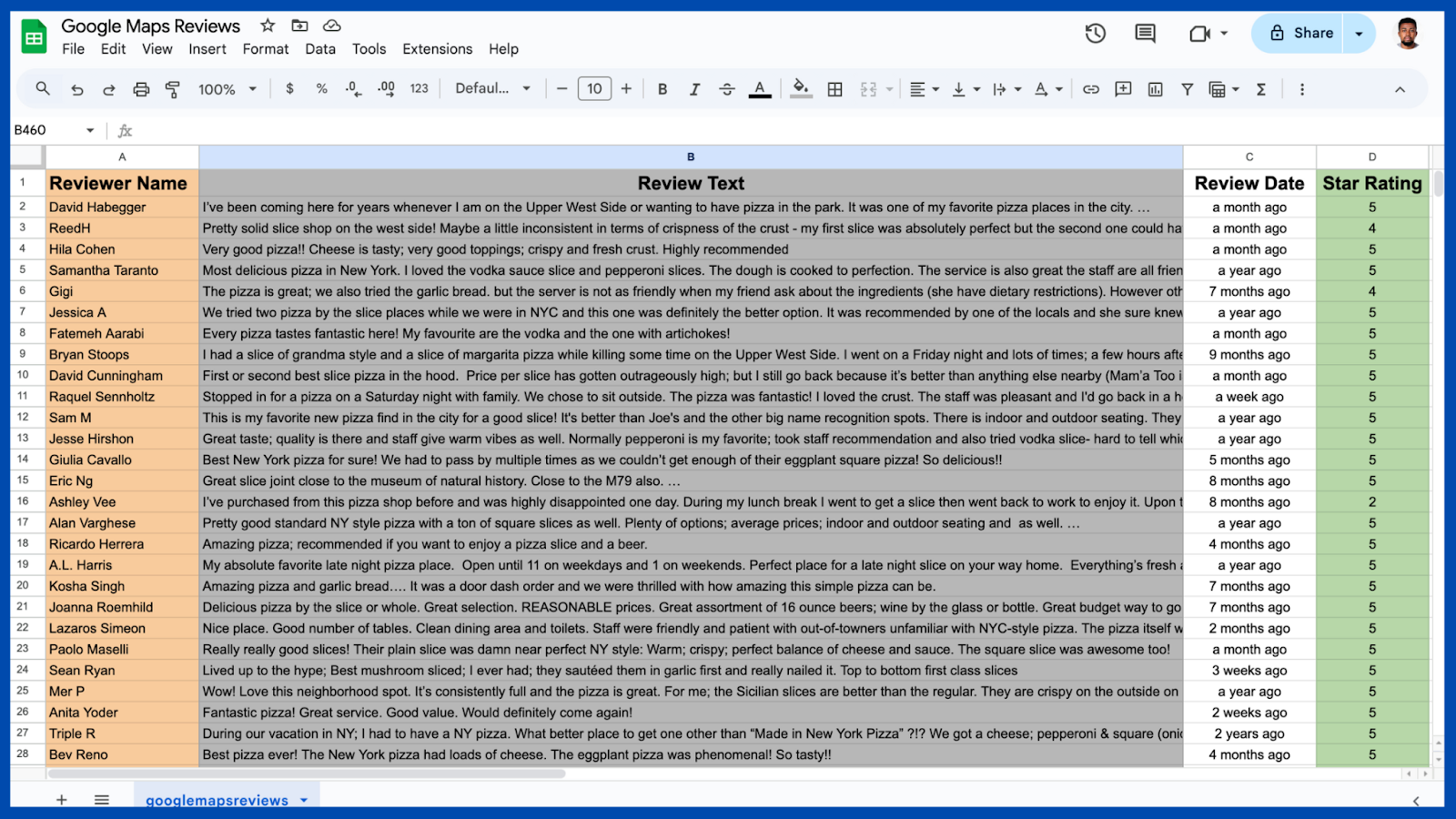
Extracted data from Google Maps
Now that you have these reviews, you can use them to leverage the information contained in multiple use cases. You can perform analysis to gauge customer satisfaction and identify trends that can be used to help businesses understand their stronger and weaker areas.
Conclusion
In this article, we explored a hands-on approach to extracting reviews from Google Maps using Puppeteer, along with proxy authentication, dynamic scrolling, and efficient data extraction. By integrating Bright Data's scraping browser, we successfully mitigated anti-scraping challenges, ensuring a smooth data-gathering process.
This script serves as a powerful example of how web scraping can help gather valuable data for market research, customer sentiment analysis, and competitive benchmarking. By automating the review collection process, businesses can unlock insights at scale that would otherwise be challenging to gather manually.
Comments
Loading comments…