I hope everyone is going through the latest happenings in the world of Large Language Models (LLM). When the first Generative Pre-Trained Model (GPT) has come out, people were very amazed by its generative capabilities. However, this technology went into mainstream when it was nurtured by OpenAI and a product by name ChatGPT was released.

But the model that OpenAI was using was never open to public and many were not aware of the methodology that they were using for the text generation. But, the Open source community was not far behind and they had started to provide many open source models that could be fine tuned for a use case. These models can be used for small and specific tasks by training them on our custom data set.
However, people were amazed at the speed with which ChatGPT responds, but the open source models would take more that 6 seconds for response, if the GPU used is small. The reason being, GPT uses an auto regressive approach during inference.
What is auto regressive approach ?
Whenever we want to ask a question to the GPT model, we ask it using a prompt. The model would then follow the below process:
- Take the prompt as model input, and predict the immediate next token
- This next token is once again added to the prompt, and another token is predicted
- Similarly, the output of one step is added to the input of a next step, till we receive the end of sentence or STOP token
- All the tokens predicted till now, are decoded and then sent back
The process of constructing the final sentence through a step by step inference is called as an auto regressive approach.
If the generation tokens size is 512, then it means that we are performing inference of the model 512 times, which usually takes time when we are doing inference with Open Source models.
What is the solution now ?
If you have taken a look at the method of generation of Chat GPT of OpenAI, it is a streaming response. This means that, the first word prints and the subsequent words print after the first word.
We can follow a similar strategy while hosting our custom Open source models as well.
Just consider a hypothetical scenario, you have used an Open source model like LLama2–7b-chat-hf. You have fine tuned it on your dataset. But, when you want to deploy it in production, you are really worried about the speed of its response, which is taking 2 to 3 seconds on a T4 GPU, whereas Open AI would give the response in less than a second. The solution is that, you should consider building a streaming service, so that as soon as the model predicts, you stream it back to your front end, showing a very less latency in your open source model prediction. The overall prediction time would still remain the same. But, nevertheless you can keep your user engaged by giving them the data that they want.
Simple example of streaming in FAST API
In this article, we are using Fast API, to host our model. Fast api does have a streaming class, where it can stream the responses of the request it gets.
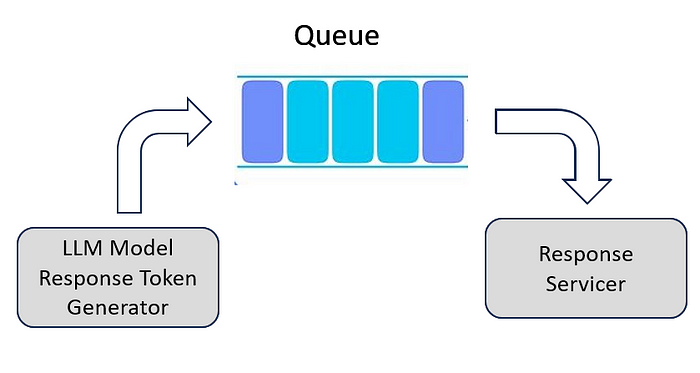
If you go back to the basics of Data structure, you would require something like a Queue. The generator would put the data into the Queue, and the server would read data out of the queue, and transmit as a response.
The architecture for the data streaming application will be as below:
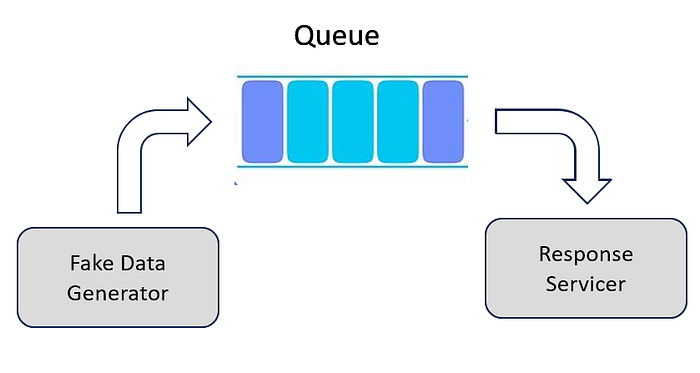
Let’s build a fake data streamer now, to understand the underlying principle of streaming in Fast API. We also intialize the queue in the process. It is preferred to use the Queue instead of collections deque, as the former provides better synchronization and thread support.
from fastapi import FastAPI
from queue import Queue
# creating a fast application
app = FastAPI()
# initializing the queue
streamer_queue = Queue()
# fake data streamer
def put_data():
some_i = 20
for i in range(20):
streamer_queue.put(some_i + i)
In order to start the generation process, we need to initialize a thread, which runs the put_data function which adds data into the streamer queue.
# Creation of thread
def start_generation():
thread = Thread(target=put_data)
time.sleep(0.5)
thread.start()
Now that we have developed our fake generator, we would need a server or a consumer, that would read the data out of the queue whenever available, and send it out.
# This is an asynchronous function, as it has to wait for
# the queue to be available
async def serve_data():
# Optinal code to start generation - This can be started anywhere in the code
start_generation()
while True:
# Stopping the retreival process if queue gets empty
if streamer_queue.empty():
break
# Reading and returning the value from the queue
else:
value = streamer_queue.get()
yield str(value)
streamer_queue.task_done()
# Providing a buffer timer to the generator, so that we do not
# break on a false alarm i.e generator is taking time to generate
# but we are breaking because the queue is empty
# 2 is an arbitrary number that can be changed based on the choice of
# the developer
await asyncio.sleep(2)
Now, finally we need to write our endpoint. The endpoint will be calling serve data function and the response of the function will be sent to the front end
# Using the endpoint by name /query-stream
@app.get('/query-stream/')
async def stream():
# We use Streaming Response class of Fast API to use the streaming response
return StreamingResponse(serve_data(), media_type='text/event-stream')
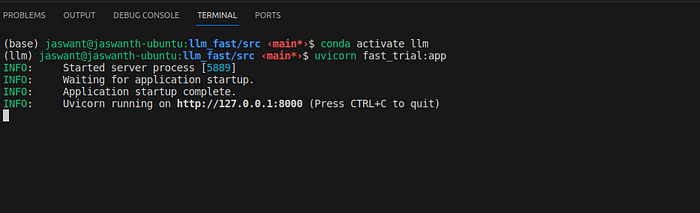
Now, that the entire code is ready, we create a file by name fast_trial.py and load it using the command
uvicorn fast_trial:app
The FastAPI server would start up as shown in the below image:
Now, in order to test our fast api streaming, we create a file by name stream_test.py, and put the following content in it
# using requests library to check the response
import requests
# the stream has started in the local host
url = "http://127.0.0.1:8000/query-stream/"
# sending a request and fetching a response which is stored in r
with requests.get(url, stream=True) as r:
# printing response of each stream
for chunk in r.iter_content(1024):
print(chunk)
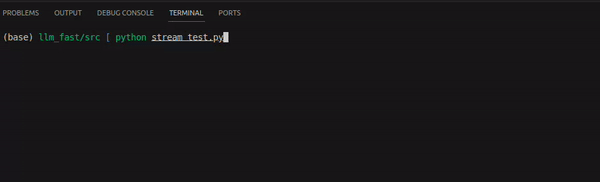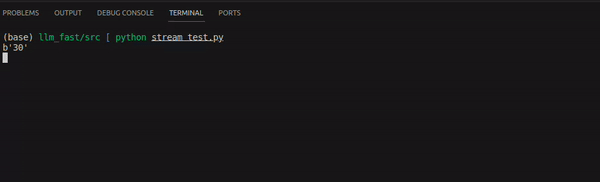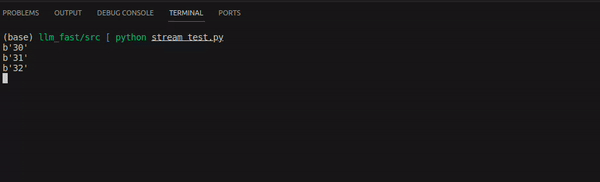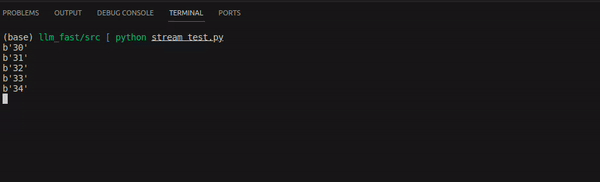
After executing the above script, the response received will be in below format:
How do we extend the same concept for LLM ?
In the example seen above, we created a fake data streamer, that puts data into the queue, but in case of LLM, we need to find a function that does the work of the data streamer and puts each word into the queue, and stop keeping words into the queue when the stop signal is received.
We need to update the architecture for LLM response generator (where the fake data streamer got replaced with LLM Model Response Token Generator) as shown below:
Fortunately, we have couple of classes implement in Hugging Face which does the above work. One is the BaseStreamer class, and another one is the inherited implementation of the above mentioned BaseStreamer class called as TextStreamer.
Let us take a look at the code of BaseStreamer class, from HuggingFace source libraries
class BaseStreamer:
"""
Base class from which `.generate()` streamers should inherit.
"""
def put(self, value):
"""Function that is called by `.generate()` to push new tokens"""
raise NotImplementedError()
def end(self):
"""Function that is called by `.generate()` to signal the end of generation"""
raise NotImplementedError()
It is defined as an abstract class, which has two methods put and end to be implemented.
put -> Method that chooses what happens to the new tokens pushed by the model.generate() function
end -> Method that chooses what to do when the stop signal is pushed by the model.generate() function
The TextStreamer inherits the BaseStreamer class and implements the put function in the following way:
- Initializes a token cache list, to convert set of tokens into words,
- Each token received by put function converted to a word by the decoder,
- Each word is checked and,
- If the word received ends with a new line, the cache is flushed,
- If the word received is a chinese charecter, it gets assigned to printable text which will printed by the function on_finalized_text,
- Else, it will take all the words in cache until a blank space is found and prints to the screen, by calling the function on_finalized_text
How is the above implementation different from the streaming implementation that we discussed ?
The above implementation uses a cache list, but in case of the Fast API response we are using a Queue. So, our implementation, needs to contain a class that takes the Queue as an input, and feeds the words to the queue, in the on_finalized_text function.
Let’s implement our custom streamer to modify the above function, which inherits the above mentioned TextStreamer class
# Contents of streamer.py file
# Importing the TextStreamer class from transformers
from transformers import TextStreamer
# Defining a custom streamer which inherits the Text Streamer
class CustomStreamer(TextStreamer):
def __init__(self, queue, tokenizer, skip_prompt, **decode_kwargs) -> None:
super().__init__(tokenizer, skip_prompt, **decode_kwargs)
# Queue taken as input to the class
self._queue = queue
self.stop_signal=None
self.timeout = 1
def on_finalized_text(self, text: str, stream_end: bool = False):
# Instead of printing the text, we add the text into the queue
self._queue.put(text)
if stream_end:
# Similarly we add the stop signal also in the queue to
# break the stream
self._queue.put(self.stop_signal)
Now that we created our custom streamer, we also need to make changes to the fast main file.
Load the Model and Tokenizer
We can use any open source model or even our fine tuned model. In this example a fine tuned model has been used which was fine tuned using QLoRA. A specific load_model function has been written and used over here. Please use your own function for loading the model and tokenizer.
from load_model import load_model
model, tokenizer = load_model()
Initialize the streamer
The custom streamer that we created needs to be initialized
from streamer import CustomStreamer
streamer_queue = Queue()
streamer = CustomStreamer(streamer_queue, tokenizer, True)
Develop a generation method
This is the method which
- takes the query as an input,
- injects the query into a prompt,
- starts a thread with model.generate()
def start_generation(query):
# Custom prompt template, can be replaced based on the use case
prompt = """
# You are assistant that behaves very professionally.
# You will only provide the answer if you know the answer. If you do not know the answer, you will say I dont know.
# ###Human: {instruction},
# ###Assistant: """.format(instruction=query)
# Converting the inputs to tokens for prediction
inputs = tokenizer([prompt], return_tensors="pt").to("cuda:0")
# key word arguments that are provided to the model.generate()function
# Includes, inputs, max_tokens, streamer, temparature
generation_kwargs = dict(inputs, streamer=streamer, max_new_tokens=64, temperature=0.1)
# Starting the thread with the stream
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
Develop a Response Generator
The above method is used to put the LLM response into the queue. We would need a method which needs to be used to retrieve the data from the queue and present it to the front end
It takes the query as an input, and It does
- Initiate the previous generation process with the query
- Start an infinite loop
- Get an output from the queue
- If output is None (stop_signal), then it breaks
- It yields the value
- sleeps for 0.1 s using asyncio.sleep()
async def response_generator(query):
# Starting the generation process
start_generation(query)
# Infinite loop
while True:
# Retreiving the value from the queue
value = streamer_queue.get()
# Breaks if a stop signal is encountered
if value == None:
break
# yields the value
yield value
# provides a task_done signal once value yielded
streamer_queue.task_done()
# guard to make sure we are not extracting anything from
# empty queue
await asyncio.sleep(0.1)
Modify the end point
Finally, we need to modify the end point, such that it takes query as a get request parameter and sends it to the response generator function.
@app.get('/query-stream/')
async def stream(query: str):
print(f'Query receieved: {query}')
return StreamingResponse(response_generator(query), media_type='text/event-stream')
Our final code is ready, let us create a file by name fast_llm.py and copy all our code there. The final code looks like below:
# Contents of fast_llm.py
from fastapi import FastAPI
import asyncio
from fastapi.responses import StreamingResponse
from load_model import load_model
from streamer import CustomStreamer
from threading import Thread
from queue import Queue
app = FastAPI()
# Loading the model
model, tokenizer = load_model()
# Creating the queue
streamer_queue = Queue()
# Creating the streamer
streamer = CustomStreamer(streamer_queue, tokenizer, True)
# The generation process
def start_generation(query):
prompt = """
# You are assistant that behaves very professionally.
# You will only provide the answer if you know the answer. If you do not know the answer, you will say I dont know.
# ###Human: {instruction},
# ###Assistant: """.format(instruction=query)
inputs = tokenizer([prompt], return_tensors="pt").to("cuda:0")
generation_kwargs = dict(inputs, streamer=streamer, max_new_tokens=64, temperature=0.1)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
# Generation initiator and response server
async def response_generator(query):
start_generation(query)
while True:
value = streamer_queue.get()
if value == None:
break
yield value
streamer_queue.task_done()
await asyncio.sleep(0.1)
@app.get('/query-stream/')
async def stream(query: str):
print(f'Query receieved: {query}')
return StreamingResponse(response_generator(query), media_type='text/event-stream')
Now that we have finished, lets test out our streamer
For this we need to create a stream_test.py
import requests
# Sending the query in the get request parameter
query = "Who are you?"
url = f"http://127.0.0.1:8000/query-stream/?query={query}"
with requests.get(url, stream=True) as r:
for chunk in r.iter_content(1024):
print(chunk)
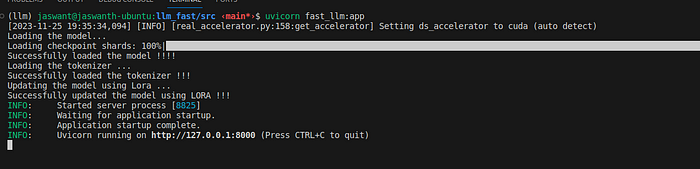
Now, let us start the above created server, using the command
uvicorn fast_llm:app
It will take some time to initialize, as we need to load the model as well.
The script has started:
Once we run the stream_test.py file, we get the following response:

We can see that, the entire response looks fast, as it is being streamed. Without streaming, it will give a sense that our custom Local LLM is very slow.
What did we achieve ?
Till now we have seen, how to achieve the a response streaming of Open Source LLM which has been fine tuned and running locally. We have looked at a method in which, we can provide a feel of reduced latency by streaming each token when the model is being inferenced in an auto regressive manner.
Of course, you can say that there are tools out there which does all these things for use like VLLM, LangStream etc., why do we need to know these. I would prefer doing things from scratch and understanding things from the ground basics. The point of this tutorial is to show that, we dont need the fancy packages out there, we just need to gather understanding of simple concepts. Here, we used the Hugging face transformers package and FastAPI, which are quite the foundation level packages. Using this understanding, we can build more complex packages by ourselves, and reduce our reliance on fancy packages out there.
Where can you go from here?
Now that, you have understood the basics of inference streaming of LLM, we can take it a level further, by
- Making it a post request
- Keeping a front end, and polishing the response to be in much presentable format
- Using sessionization, so that queues are not shared when multiple requests come at the same time
- Containarize the application, and push to kubernetes for deployment
- Use databases for storing the requests and response
- Improving the Streamer class, by using a new data structure instead of a Queue
- Improve security to the application
- And a bunch of other software engineering stuff
Conclusion
Thanks for reading this article. Please try out these techniques. The code presented in this article can be found here.
If you have any questions about the content, or want to discuss more, please write to me at jaswanth04@gmail.com.
Comments
Loading comments…