Hope everyone has read my previous article about deploying Local or Fine-tuned LLMs in FastAPI and achieve streaming response in the same. However, I have received few requests on how to extend the same concept to closed source models of OpeanAI, Google etc. Hence this article will be an extension of the previous article. Please read that, at least the first part to know more about the basics of streaming in FastAPI.

In the previous article we have learnt about the following:
- Introduction — What is the problem statement that we are solving by using Streaming ?, What are auto regressive models ?, What is streaming ?
- Basics of FastAPI Streaming — Architecture and Implementation of a simple streaming application using fake data streamer
- We also understood the Producer-Consumer model of sending the tokens into the queue, which is then consumed and streamed using FastAPI
- We also extended the above discussed FastAPI Streaming concept to Locally deployed LLMs, just using Hugging Face generate, streamer functions
- We have also listed the next steps, and how can the current concept be improved.
In this article we are going to focus on the similar steps using Langchain
Architecture to be used for Langchain
As in the previous article, we would still be using a queue, and a serving function. However we need to modify the generate function that would be populating the queue token by token.
Architecture of Langchain based token generator:
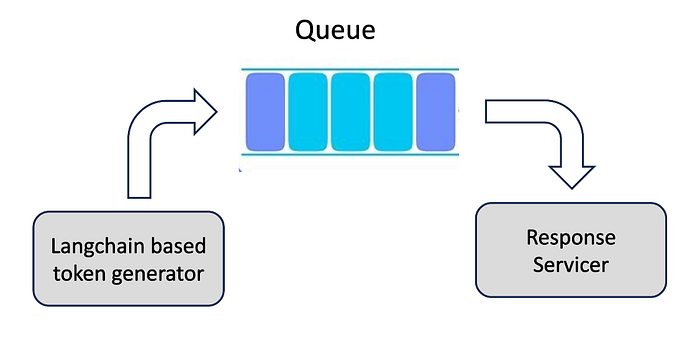
Handlers in Langchain
Langchain has various sets of handlers. The main handler is the BaseCallbackHandler. These handlers are similar to an abstract classes which must be inherited by our Custom Handler and some functions needs to be modified as per the requirement.
The functions that are of interest to us in the present case are the following:
- on_llm_new_token — This function decides on what to do in the case of a new token arrival. As per the existing concept, we should keep the new token in the streamer queue
- on_llm_end — This function decides on what to do in the case of the last token. As per the existing concept we add a stop signal in the queue to stop the streaming process.
Let us see how the handler looks like. Each line is commented so that you could understand what is happening in the same
%handler.py
# save the below code in a file by name handler.py
# Importing the necessary packages
from langchain.callbacks.base import BaseCallbackHandler
from langchain.schema.messages import BaseMessage
from langchain.schema import LLMResult
from typing import Dict, List, Any
# Creating the custom callback handler class
class MyCustomHandler(BaseCallbackHandler):
def __init__(self, queue) -> None:
super().__init__()
# we will be providing the streamer queue as an input
self._queue = queue
# defining the stop signal that needs to be added to the queue in
# case of the last token
self._stop_signal = None
print("Custom handler Initialized")
# On the arrival of the new token, we are adding the new token in the
# queue
def on_llm_new_token(self, token: str, **kwargs) -> None:
self._queue.put(token)
# on the start or initialization, we just print or log a starting message
def on_llm_start( self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any ) -> None:
"""Run when LLM starts running."""
print("generation started")
# On receiving the last token, we add the stop signal, which determines
# the end of the generation
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""Run when LLM ends running."""
print("\n\ngeneration concluded")
self._queue.put(self._stop_signal)
Integrating the handler in main
We have seen how to write the custom handler. Now let us see, what should be in the main file which contains the fastapi code
We need to first create an object of the custom handler and add it to the api. During the time of writing this article, I was using langchain-0.1.0.
During the time of writing this article, Langchain has a separate package for Open AI usage. The library that I am using is langchain-openai==0.0.2.post1.
In the beginning, we initiate the handler and provide the handler to the LLM.
%fast_langchain.py
#Importing all the required packages
from fastapi import FastAPI
import asyncio
from fastapi.responses import StreamingResponse
from handlers import MyCustomHandler
from threading import Thread
from dotenv import load_dotenv
from queue import Queue
#Separate package for OpenAI
from langchain_openai import ChatOpenAI
#Importing Message templates
from langchain.schema.messages import HumanMessage
# loading the OPENAI_API_KEY
load_dotenv()
# Creating a FastAPI app
app = FastAPI()
# Creating a Streamer queue
streamer_queue = Queue()
# Creating an object of custom handler
my_handler = MyCustomHandler(streamer_queue)
# Creating the llm object and providing the reference of the callback
llm = ChatOpenAI(streaming=True, callbacks=[my_handler], temperature=0.7)
Now is the time to build the generator that populates the queue with the tokens
Here, we need to do the following
- Write a generate function — The generate function, in this case is the llm.invoke function. This gives the response in the form of an AIMessage Template
- Create a Thread — A thread needs to be initiated with the above function as a target. Since the llm.invoke function returns an AIMessage, we wont be able to provide it as a target to the Thread. Therefore, we need to write a wrapper function and provide it as a target to the thread
- Start the Thread — This is a straightforward process
Wrapper Function for generation
The wrapper function to be used for the generation in this example would have a single line. Since the response is being rendered as a streaming service we dont have much use of returning the response. However, if you are extending this logic to any of your existing applications where you do something extra, like history maintenance, storing the response in a database, please extend this function with the desired logic or functionality.
Lets look at the generator functions.
%fast_langchain.py
# Generate wrapper function as discussed above
# Please extend this with the required functionality
# We are not returning anything as llm has already been tagged
# to the handler which streams the output
def generate(query):
llm.invoke([HumanMessage(content=query)])
def start_generation(query):
# Creating a thread with generate function as a target
thread = Thread(target=generate, kwargs={"query": query})
# Starting the thread
thread.start()
The consumer function
This is the function that returns a generator that consumes the words put in the queue. The following is the logic:
- Start the generation process
- Start an infinite loop
- Get the value from the streamer queue
- If value is stop_signal, break the loop, else yield the value
%fast_langchain.py
async def response_generator(query):
# Start the generation process
start_generation(query)
# Starting an infinite loop
while True:
# Obtain the value from the streamer queue
value = streamer_queue.get()
# Check for the stop signal, which is None in our case
if value == None:
# If stop signal is found break the loop
break
# Else yield the value
yield value
# statement to signal the queue that task is done
streamer_queue.task_done()
# guard to make sure we are not extracting anything from
# empty queue
await asyncio.sleep(0.1)
Create the end point
Finally, we need to create the end point, such that it takes query as a get request parameter and sends it to the response generator function.
%fast_langchain.py
@app.get('/query-stream/')
async def stream(query: str):
print(f'Query receieved: {query}')
return StreamingResponse(response_generator(query), media_type='text/event-stream')
Now that we have finished, lets test out our streamer
For this we create a notebook with the following cells
import requests
# Sending the query in the get request parameter
query = "How to print hello world in python"
url = f'http://127.0.0.1:8000/query-stream/?query={query}'
with requests.get(url, stream=True) as r:
for chunk in r.iter_content(1024):
print(chunk.decode('utf-8'), end="")
We need to start our server, using the below command in the command line
uvicorn fast_langchain:app
It would be started similar to below.
Uvicorn server started:

Now, lets run the notebook to see the response.
Response of the Streaming:
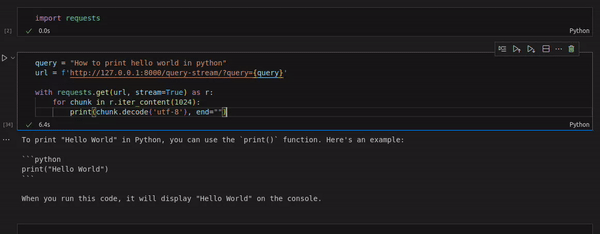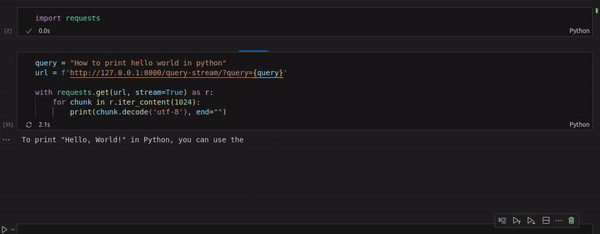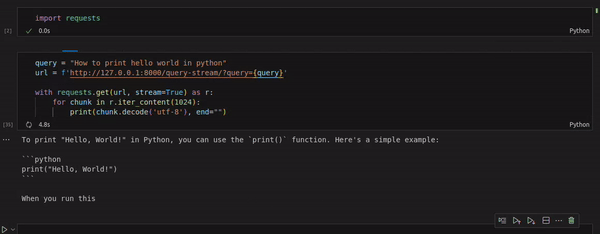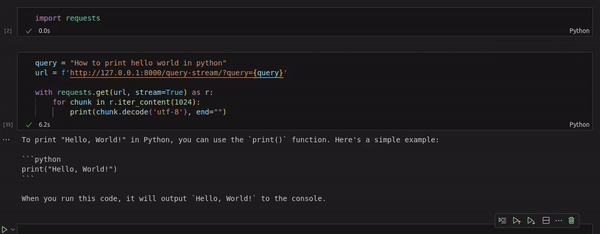
We see that we are able to get the response in a streaming fashion.
Where to go from here ?
In the above example most of the changes were done in the producer side, with the consumer function being largely similar to what has been done in the previous article.
We have seen, how to obtain a streaming response using callback handlers in Langchain for OpenAI. We have only seen the case of general query prediction
- If you want to use RAG with Retrieval QA, you can provide the llm to the retrievalQA object which can generate the response. Just instantiate the retrievalQA object in the global context, and modify the generate function accordingly
- Similarly you can use the above logic for agents as well
- You can also look at other functions in the BaseCallbackHandler class, which can provide specific functionalities for Retrival classes and Agent classes. The functions are — on_retriever_start, on_retriever_error, on_retriever_end, on_agent_action, on_agent_finish
- As mentioned in the previous articles, you can improve this code by wide variety of things — adding a frontend, making the requests as POST requests, adding more security, containerization and bunch of other software engineering stuff
Conclusion
In this article we have seen — basics of handlers, modification of the producer to use the handler, minimal modification of the consumer and next steps for improvement of the application. Such applications can be very happily used in production with some additional changes from security, front end etc.
The code used in the article is uploaded here.
If you have any questions about the content, or want to discuss more, please write to me at jaswanth04@gmail.com.
Comments
Loading comments…