
A vendor-neutral reference architecture and a set of operating practices for industrial and manufacturing AI — from the cloud control plane down to constrained hardware on the line.
Manufacturing and other industrial organizations are now running two kinds of AI side by side. One is the familiar predictive stack — yield models, vision-based defect detectors, failure forecasts — trained on equipment and process data. The other is a generative layer of copilots and agents that answer questions over specifications, query operational databases in plain language, and read engineering documents. The two are usually built by separate teams on separate tooling, and that split is where governance, security, and delivery begin to fray.
This piece lays out a way to bring both under one control plane, and argues for a single operating discipline that serves them both. The throughline is simple: once a generative system is baselined, evaluated, gated, and monitored the way a predictive model already is, one delivery pipeline can reasonably cover both — even as workloads move from the cloud out to the factory floor.
If a generative system can be evaluated and released with the same rigor as a predictive model, the two need not live in separate worlds.
1. The reference architecture
A governance hub gives both lifecycles one control plane — private networking, role-based access control, content safety, and cost governance. Inside it, two project workspaces hold the predictive models and the generative systems, while a shared registry records versions and lineage, and managed endpoints serve online and batch workloads. A multi-source data estate feeds the hub; an integration plane wires outputs into enterprise systems; an observability layer captures metrics, traces, and quality signals.
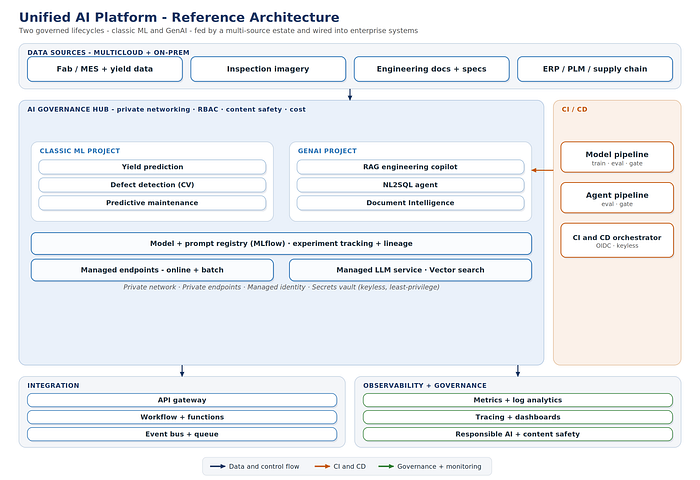
Figure 1. Two governed lifecycles — classic ML and generative AI — under one governance hub.
One detail matters more than it looks: the shared registry is built on MLflow. It records experiments, parameters, metrics, model versions, and prompt configurations with full lineage — the same backbone whether the artifact is a gradient-boosted defect model or a retrieval prompt. Versioning prompts and indexes alongside models is what lets you trace and roll back a generative regression exactly like a model regression.
Edge versus cloud — the part most cloud-centric designs miss
On a plant floor you cannot assume connectivity for time-critical work. So the architecture splits execution into two planes under the one hub. The cloud inference plane serves heavy work where latency is relaxed: large-model serving, deep vector search, batch scoring. The industrial edge plane runs latency- and safety-critical work — in-line optical inspection, high-frequency forecasting — on edge gateways and industrial PCs at the line.
The hub is what makes this safe at scale. Models and prompts are versioned and signed centrally, then pushed to the edge as immutable, signed containers; vision models are cross-compiled (ONNX or TensorRT profiles) and language models quantized in the cloud before deployment. In the other direction, edge telemetry, model-health metrics, and drift signals stream back to the hub — so a model running disconnected on the floor stays governed, monitored, and re-trainable from the center.
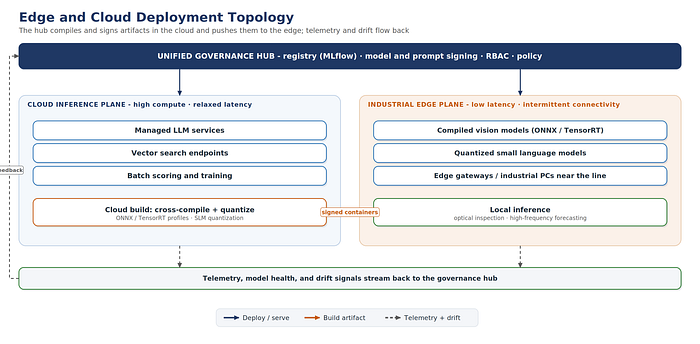
Figure 2. Sign and compile centrally, push immutable containers to the edge, stream telemetry back.
Keeping the retrieval index fresh
Generative quality depends on an ingestion pipeline that keeps the retrieval index current as engineering documents change — and in a plant, SOPs, CAD sheets, and quality records change weekly. A document update should trigger re-processing, not a manual rebuild. The pipeline runs five stages: extraction of layout, tables, and text; hierarchical chunking that preserves structure; metadata harvesting (facility, equipment, author, version); bi-encoder embedding; and indexing into a vector store, with each index version cataloged in the registry.
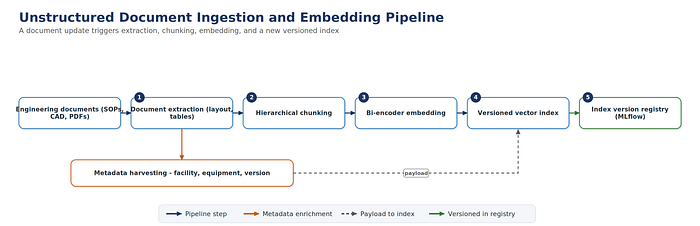
Figure 3. A document update triggers extraction, chunking, embedding, and a new versioned index.
2. Baselining the predictive lifecycle
Before tuning, a candidate model has to clear a baseline floor — the score of a naive predictor like a majority-class classifier or a last-value forecaster. If it can’t beat that by a defined margin, it doesn’t advance. Beyond the floor, the metric has to match the task and, above all, the class balance:
Defect / anomaly detection is usually severely imbalanced, so accuracy misleads — use precision, recall, F1, and especially the area under the precision-recall curve (often recall at a fixed precision).
Regression (yield, remaining useful life) uses RMSE, MAE, and R².
Calibration matters when a probability drives an automated decision — track Brier score and expected calibration error.
Promotion is a champion-versus-challenger gate: register only if the candidate beats the deployed model on a frozen, time-ordered or stratified holdout. MLflow autologs each run and carries the chosen version through staged promotion, so every baseline and challenger stays reproducible.
Choosing a foundation model for the generative side is the same exercise: compare candidates on public benchmarks like MMLU and HumanEval, then re-test on a private, representative slice — because the public number rarely predicts your domain.
3. A drift taxonomy for the factory
Models decay as the world drifts from their training data. In manufacturing the causes are concrete, and the most useful split is operational — what you can catch without labels, and what you can’t:
Data / covariate drift — a new recipe, tool, lot, or recalibrated sensor. Detectable label-free with PSI, JS/KL divergence, or KS tests.
Prediction drift — the output distribution moves. Also label-free, and often the earliest warning.
Concept drift — the input-to-target relationship changes as a tool ages or a new failure mode appears. The dangerous one: inputs look normal while accuracy quietly decays. Confirmable only against labels, which in a fab arrive late (final test, field returns); detectors like ADWIN and DDM watch the label stream.
Data-quality / pipeline drift — a schema change or unit flip masquerading as data drift. The rule: confirm the pipeline is intact before you retrain.
Label, seasonality, and upstream-cascade drift round out the picture.
A common convention: PSI below 0.10 is stable, 0.10–0.25 is worth watching, above 0.25 is significant.
4. RAG, direct generation, or an agent?
Three patterns cover most generative work, and the trick is to escalate only when you must.
Retrieval-augmented generation (RAG) grounds answers in retrieved content so they cite sources instead of leaning on parametric memory. Best for cited Q&A over specs, procedures, and knowledge bases. Lower hallucination risk; medium cost.
Direct generation uses the model alone — drafting, summarizing, classifying, translating — where no corpus is needed. Lowest cost; highest hallucination risk if facts matter.
Agents plan and act: they call tools, hold state, and loop until a goal is met. Best for multi-step work — triage-then-remediate, or natural-language-to-SQL followed by an action. Highest cost and failure surface.
The rule of thumb: start at RAG, and reach for an agent only when the task genuinely needs more than one step or a tool call.
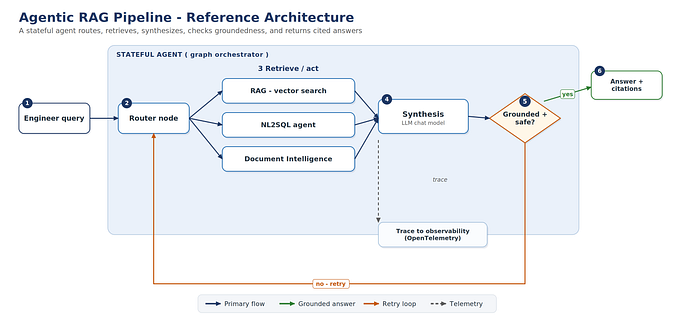
Figure 4. A stateful agent routes, retrieves, synthesizes, checks groundedness, and returns cited answers.
5. Evaluating generative systems — and trusting the judge
Generative systems need more than one accuracy number. Three families of evaluators apply: model-graded (a strong model judges coherence, fluency, relevance, and groundedness), reference-based (F1, BLEU, ROUGE, METEOR against a gold answer), and safety (harmful content, prompt-injection resistance). For agents, add process evaluators (were the right tools called correctly?) and outcome evaluators (intent resolution, task adherence).
Model-graded scoring is only trustworthy if you control its biases. Three safeguards earn their keep:
Position-bias control — swap option order so the judge doesn’t favor a slot.
Verbosity control — length-normalize so a longer answer isn’t rewarded over a shorter, correct one.
Few-shot calibration — anchor the scale with human-verified boundary examples.
Run evaluation offline as a pre-deployment gate and online as controlled A/B. The unifying idea is evaluation as a release gate: a regression below threshold blocks promotion, exactly as a metric regression blocks a model.
6. One delivery pipeline for both
The pipeline applies the same discipline to both lifecycles. Triggers are path-filtered so a change runs only the affected use case; automation authenticates with federated identity rather than stored secrets; one tested pipeline is reused by thin per-use-case callers; the main branch is protected; and security scanning runs on every change.
# Thin per-use-case trigger that calls one shared, tested pipeline
on:
pull_request:
paths: ["use_case/**", "lib/**"] # only run what changed
jobs:
evaluate-and-deploy:
uses: ./pipelines/shared_pr_pipeline.yml # one implementation
secrets: inherit # federated identity
Two gates govern promotion. The model gate registers a predictive model in the MLflow registry only when it beats the champion on a holdout. The evaluation gate runs the generative system against its evaluation set and blocks on a quality or safety regression. Deployment is a safe rollout — blue-green or canary — with traffic shifted gradually behind the endpoint.
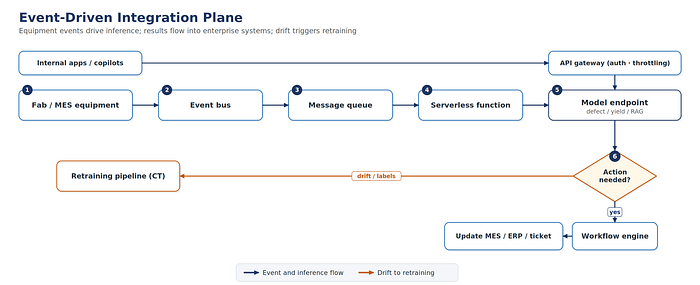
Figure 5. Events drive inference; results flow into enterprise systems; drift triggers retraining.
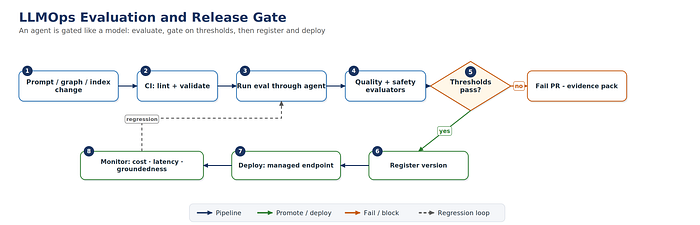
Figure 6. An agent is gated like a model: evaluate, gate on thresholds, then register and deploy.
7. Closing the loop in production
Monitoring closes the loop. Operational telemetry tracks latency, token cost, error rate, and throughput against service-level objectives — with tighter latency budgets for edge inference — while quality and groundedness scores are sampled live and compared to their evaluation baselines. The label-free drift signals from Section 3, gathered from cloud and edge alike, raise early alarms and trigger retraining once labels confirm a real concept shift; on the generative side, falling retrieval or groundedness scores trigger re-indexing or re-tuning.
Takeaway
Industrial organizations no longer choose between predictive ML and generative AI — they run both, often against the same equipment and the same engineering record. A generative system can be baselined, evaluated, gated, and watched for drift on the same lifecycle a model already follows, so one governance plane and one delivery discipline can cover both. Two habits do most of the work: catch distribution shifts early without waiting for labels, and refuse to ship a model or an agent that regresses against its evaluation set. Neither is new on its own — the point is that together they compose into a single operating model that survives the move from the cloud down to constrained hardware on the line.
References available on request: RAG (Lewis et al. 2020; Gao et al. 2023), ReAct (Yao et al. 2023), concept drift (Gama et al. 2004/2014; Bifet & Gavaldà 2007), evaluation metrics (Papineni 2002; Lin 2004; Banerjee & Lavie 2005), benchmarks (Hendrycks et al. 2021; Chen et al. 2021), MLflow (Zaharia et al. 2018), MLOps (Kreuzberger et al. 2023), LLM evaluation survey (Chang et al. 2024).
Comments
Loading comments…