A 1 AM Wake-Up Call
A friend showed up at the coffee shop looking hollowed out. Dark circles. Half-drunk espresso already going cold.
“Compliance called us at 1 AM,” he said. “GDPR request. They needed full data lineage on a customer record.”“And?”“Our catalog had nothing. No lineage. No audit trail. No paper trail at all. Engineering was completely blind.” He turned the cup in his hands. “Turns out, building a Lakehouse is the easy part. Governing it? That’s where everyone crashes.”
That conversation stuck with me. I spent the next several weeks going through architecture reviews, the Microsoft Purview documentation, and conversations with platform engineers who had lived through this exact scenario. This article is everything I found.
But here’s the thing I didn’t expect to discover: the governance problem in 2026 is no longer just about complying with GDPR or HIPAA. It is about AI. Ungoverned training data, untracked model lineage, and unclassified PII flowing into fine-tuning pipelines are the new front lines of data risk. If your team is building AI on top of an ungoverned Lakehouse, you are not just audit-exposed — you are *model-*exposed.
What You’ll Get From This Article
- The mental model behind Microsoft Purview’s three governance planes.
- How the Databricks–Purview bridge actually works in 2026 (and why the recommended Integration Runtime has changed).
- What governance debt is and how it compounds silently.
- A full pre-engineering foundation: maturity assessment, stakeholder alignment, architecture decisions, role assignments, Azure prerequisites, network topology, and POC scope — everything before you write a single line of code.
What You’ll Get From This Article
- The mental model behind Microsoft Purview’s three governance planes.
- How the Databricks–Purview bridge actually works (and why it requires a Self‑Hosted Integration Runtime — SHIR).
- What governance debt is and how it compounds silently.
- A full pre‑engineering foundation: maturity assessment, stakeholder alignment, architecture decisions, role assignments, Azure prerequisites, network topology, and POC scope, everything before you write a single line of code.
Table of Contents
- The Crisis That Nobody Planned For
- The Pitch in One Page
- Understanding Microsoft Purview
- The Databricks–Purview Bridge
- How Metadata and Lineage Actually Flow
- The Authentication Chain (Security Done Right)
- Why Unity Catalog Matters
- Governance Debt: The Silent Accumulator
- Governance as Business Value, Not Compliance Theater
- The Pitfalls of Skipping Governance
- Before You Build: The Pre‑Engineering Foundation 11.1 Step 1. Assess Your Governance Maturity 11.2 Step 2. Map Your Regulatory Landscape 11.3 Step 3. Align Your Stakeholders 11.4 Step 4. Make Your Architecture Decisions Upfront 11.5 Step 5. Define Roles and Responsibilities 11.6 Step 6. Azure Resources and Prerequisites 11.7 Step 7. Plan Your Network Topology 11.8 Step 8. Define POC Scope and Success Criteria 11.9 Step 9. Realistic POC Timeline
- What This Article Does Not Cover (Yet)
- Final Thoughts
1. The Crisis That Nobody Planned For
Starting around 2018 and continuing through the mid-2020s, regulated industries migrated aggressively from on-prem Hadoop clusters to cloud-native platforms like Azure Databricks. The migration is still ongoing. Many hybrid estates exist even in 2026 but the Lakehouse architecture has become the dominant pattern for new analytics workloads. It delivered on speed. It did not deliver on governance.
By 2021, the cracks were visible. GDPR had been in force since 2018. CCPA followed. HIPAA enforcement tightened. Basel IV introduced explicit data lineage mandates for banks. Regulators were no longer asking if you had your data in order, they were asking you to prove it, on demand, in detail.
Imagine you are a data engineer in 2026. Your Databricks pipelines spin up nightly. Streaming jobs run in seconds. Dashboards look slick. Then compliance walks over:
- Who last updated this table?
- Which datasets contain PII?
- Can you trace a specific customer record end-to-end through your pipelines?
- When was this column last classified?
- What DLP policy applies to this dataset?
These were not trivia questions. They were compliance lifelines. As reported across the Databricks community, many large organizations were stitching governance together from four or more siloed tools as late as 2022 none of which integrated natively with Databricks, and none of which talked to each other. Tracking a single record could take days of manual investigation. A crisis nobody planned for had quietly arrived.
Now add AI to the picture. Data scientists are pulling those same ungoverned tables into feature stores and training pipelines. Models train against data whose lineage nobody can prove. PII flows into fine-tuning jobs without classification labels. This is not hypothetical. It is happening across the industry right now, and it is why governance has become an AI concern, not just a compliance concern.
In the AI race, governance is not a cost, it is a competitive accelerator. Teams that can prove training-data lineage, classify sensitive inputs, and automate compliance reporting move from prototype to production weeks faster than those stuck in audit purgatory. This article helps you avoid that trap.
2. The Pitch in One Page
If you take nothing else from this article, take this:
Problem — Lakehouse adoption outpaced governance. Compliance teams cannot answer basic questions, engineers cannot trace data, auditors find gaps.
Solution — Microsoft Purview as the governance fabric, plus Databricks Unity Catalog as the authoritative metadata source, bridged via an Integration Runtime.
Value — One portal for discovery, classification, lineage, DLP, and compliance scoring across cloud, on-prem, SaaS, and the Lakehouse.
Impact — Days-long audit responses collapse into minutes. Self-service analytics grows because users trust the data. Multi-million-euro GDPR penalties become avoidable rather than inevitable.
3. Understanding Microsoft Purview
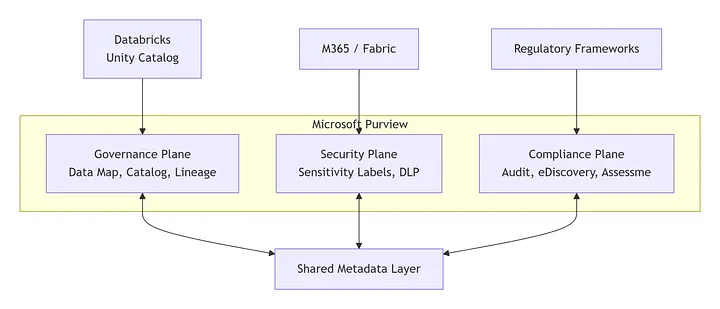
Microsoft Purview: a purpose-built governance fabric designed to span your entire data estate. If you’ve heard “Purview = data catalog,” you’re thinking too small. Purview is organized around three interconnected governance planes, and once you internalize this model, the entire portal makes sense.
Figure 1 — Purview’s three planes (Governance, Security, Compliance) converge on a single asset view across cloud, on-prem, and SaaS.
Purview acts as the single source of truth. It scans data sources (cloud, on-prem, SaaS) and catalogs schemas, column types, and classifications in one place. One portal to search for tables, check lineage, and see any sensitivity labels or DLP policies attached. No more stitching spreadsheets together at 1 AM.
Per Microsoft’s documentation, Purview unifies security, governance, and compliance into one platform, bridging tools across Azure, Microsoft 365, and Fabric to reduce duplication and complexity.
One important note for 2025/2026: if your organization is adopting Microsoft Fabric alongside Databricks, Fabric’s native Purview integration (generally available since 2024) may offer a more direct path for some workloads. The SHIR-based approach described in this article remains the standard for dedicated Databricks-on-Azure architectures.
4. The Databricks — Purview Bridge
So how does Databricks talk to Purview? It does not, not directly. Think of it as two systems that need a translator. That translator is an Integration Runtime (IR). Here is where most blog posts get out of date, so read carefully.
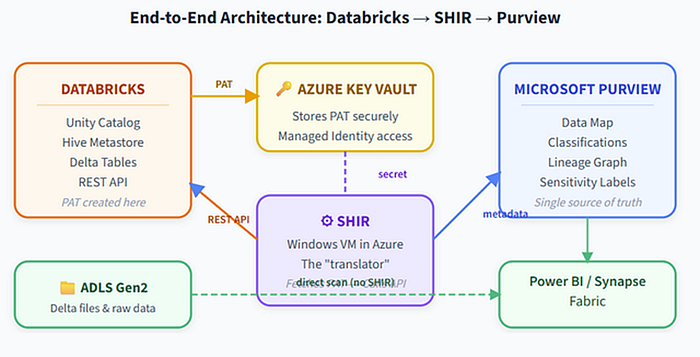
Figure 3. The IR is the only component that touches both sides. Secrets stay in Key Vault, raw data never leaves Databricks.
The Databricks ↔ Purview Bridge Databricks Workspace Unity Catalog metastore SQL Warehouse (HTTP) system.access (lineage) Azure Key Vault PAT secret (never leaves) Integration Runtime pick one Azure IR (managed) Managed VNet IR Kubernetes SHIR Microsoft Purview Data Map Managed Identity Lineage + Classifications HTTPS (PAT) metadata JSON retrieve secret
Raw data never leaves Databricks. Only metadata crosses the bridge.
4.1 Choosing the right Integration Runtime
This is the most common place teams get stuck because Microsoft’s recommended path changed. For the Unity Catalog connector specifically:
- Azure Integration Runtime. Microsoft-managed, easiest, no infrastructure to maintain. Use when Databricks is reachable over the public endpoint.
- Managed VNet IR. Microsoft-managed but injected into a virtual network via managed private endpoint. Use when Databricks is private-link only.
- Kubernetes-supported SHIR. Self-hosted on a Kubernetes cluster you operate. Use only when corporate policy forbids both of the above.
The older “SHIR on a Windows VM” pattern you will find in blog posts from 2022 and 2023 was the path for the legacy Hive Metastore connector, not the Unity Catalog connector. If you are standing up a new bridge in 2026, default to Azure IR or Managed VNet IR.
4.2 The connection mechanics
The IR connects to a Databricks SQL Warehouse over its HTTP path, authenticated by a Personal Access Token (PAT) stored in Azure Key Vault. Purview’s Managed Identity pulls the PAT from Key Vault, the IR uses it to issue read-only queries against Unity Catalog, and the resulting metadata flows back into the Purview Data Map.
Step-by-step setup:
- Create a PAT in Databricks and store it in Azure Key Vault. No hardcoded credentials, ever.
- Grant Purview’s Managed Identity “Get” permission on the Key Vault secret.
- Enable the
system.accessschema in Unity Catalog. Lineage data lives in these system tables. Without access, you will get assets but no lineage. - Register a SQL Warehouse in Databricks and note its HTTP path.
- Register Databricks as a source in Purview. Choose the Unity Catalog connector (not the Hive Metastore connector). Point it at the Key Vault secret and the SQL Warehouse HTTP path.
- Run the scan. Purview’s IR connects to the SQL Warehouse, crawls Unity Catalog, reads system tables for lineage, compiles metadata into JSON, and pushes it into the Data Map.
Crucially, Unity Catalog is a Databricks’ unified metadata service, natively stores tables, schemas, and permissions in one place with cross-workspace lineage. If you are still on Hive Metastore, the connector will grab what it can, but the picture will be incomplete (and the recommended path is to migrate).
5. How Metadata and Lineage Actually Flow
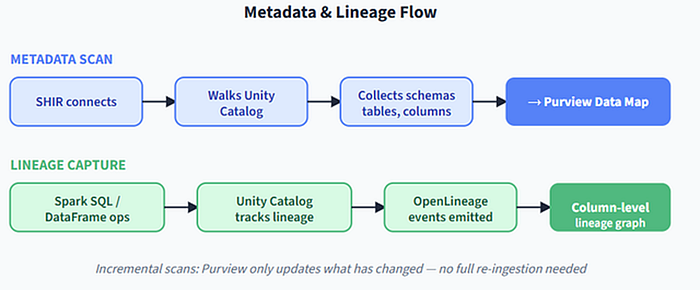
Figure 3. Two streams feed the Data Map (structural metadata and lineage) and Purview stitches them into a queryable, column-level governance graph.
Two streams feed the Data Map: structural metadata and lineage. Purview stitches them into a queryable, column‑level governance graph.
5.1 Stream A: Structure — Unity Catalog provides catalogs, schemas, tables, columns, data types. The IR queries these via the SQL Warehouse and sends a JSON payload to Purview.
5.2 Stream B: Lineage — Notebook and job runs (Spark SQL, DataFrame ops) write to system.access system tables. The IR reads these lineage edges (column‑level) and forwards them to Purview.
After the first full scan, Purview performs incremental scans — only what changed.
The result: a column‑level lineage graph showing exactly how data moves through your pipelines.
6. The Authentication Chain (Security Done Right)
Authentication Chain (Sequence) Purview Managed Identity Key Vault IR SQL Warehouse
- trigger scan
- request PAT secret
- return secret (audit-logged)
- pass PAT to IR
- auth + query
- metadata over TLS
- write to Data Map
No path requires a hardcoded secret. Every secret retrieval is audit-logged.
Press enter or click to view image in full size
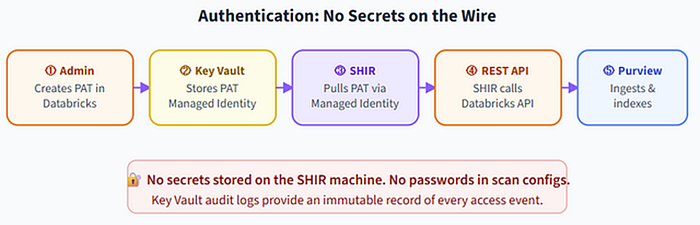
Figure 4. Secrets never leave Key Vault. The Managed Identity is the only thing that ever sees them, and every retrieval is audit-logged.
This matters because the most common breach pattern in cloud data platforms is not a zero-day exploit. It is a hardcoded token in a notebook that ended up in a public Git repo. The architecture above makes that class of mistake structurally impossible.
7. Unity Catalog: Why It Matters
Unity Catalog is Databricks’ unified governance solution for data and AI. It provides a three-level namespace (catalog.schema.table) with fine-grained access control and built-in lineage. From Purview's perspective, it is the authoritative metadata source that gets scanned and indexed.
Unity Catalog Namespace Hierarchy Metastore one per region Catalog e.g., prod_finance Schema e.g., reporting Tables structured data Views virtual tables Volumes files / unstructured Models / Fns AI assets Attached at every level grants • owners • comments • tags • lineage edges • audit history
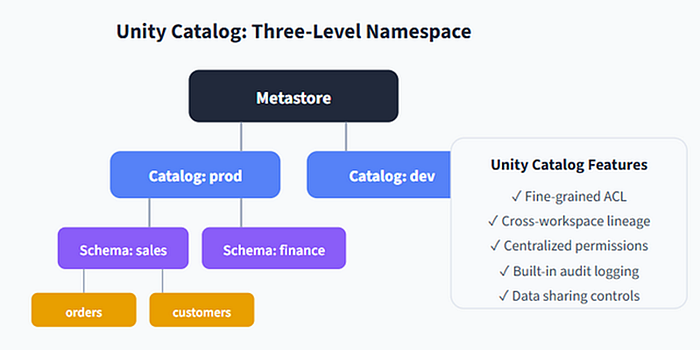
Figure 5. Unity Catalog’s three-level namespace, plus the governance attributes attached at each level (all of which Purview reads and surfaces in the Data Map).
Without Unity Catalog (that is, on legacy Hive Metastore), you will still get some metadata into Purview, but workspace-scoped silos, missing lineage, and a lack of cross-workspace governance will reduce the value of the integration dramatically.
8. Governance Debt: The Silent Accumulator
Building this bridge takes time. And on most teams, governance gets pushed off while projects ship feature after feature. The risk you accumulate during that delay is what I call governance debt.
It works exactly like financial debt: each skipped policy, each undocumented table, each untagged PII column is an unpaid bill that quietly accrues interest. Governance debt does not file Jira tickets. It does not send Slack alerts. It just sits there until it does not.
A typical scenario: your team adds a new customer-data feed. Nobody documents which pipeline produces it. Six months later, compliance asks “How is PII labeled at ingestion?” and finding the answer takes weeks of detective work across notebooks, schedulers, and tribal knowledge.
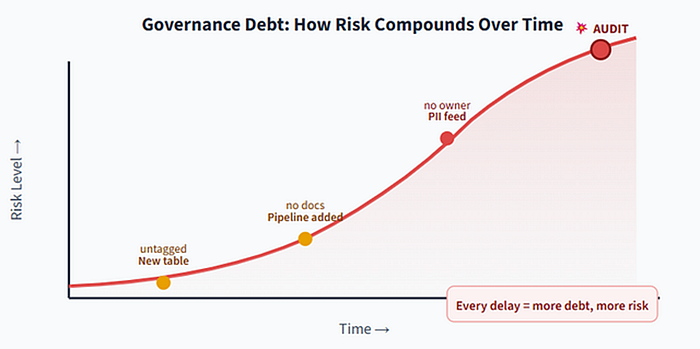
Fig 7: Governance debt compounds silently — until it explodes (usually at an audit, an incident, or a public demo)

The scary part: these issues always surface at the worst moments a regulatory audit, a security incident, a broken pipeline on demo day. What once seemed ignorable suddenly looks like a disaster.
9. Governance as Business Value, Not Compliance Theater
Let us flip the frame: governance is not a checkbox. It is a multiplier.
A well-governed Lakehouse boosts confidence across the whole organization. When a report shows bad numbers, lineage in Purview lets you pinpoint the exact upstream table that broke it, instead of guessing. Classification and labeling mean any data scientist can immediately see “this table has customer emails, so I must mask it” without asking around. Self-service analytics grows because users trust the data.
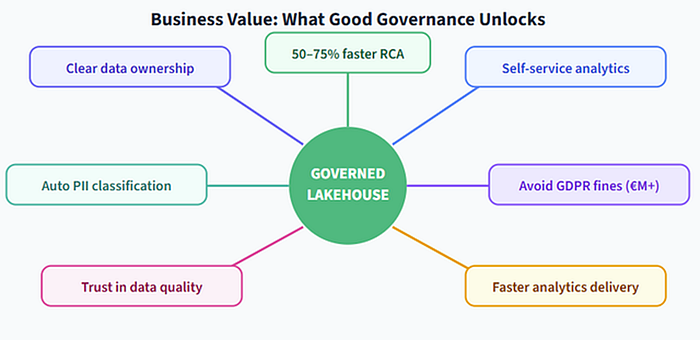
Figure 7. Governance moves you into the upper-right quadrant: fast delivery, trusted data. The other quadrants are the failure modes.
Organizations that implement end-to-end governance report dramatically faster root-cause analysis and far fewer compliance headaches. They avoid costly fines (some GDPR penalties run into the hundreds of millions of euros) and they also move faster on analytics because nobody is second-guessing the data. In a regulated industry, that is a competitive moat.
10. The Pitfalls of Skipping Governance
What if you just skip all this and hope for the best? We have seen it many times. It feels fine at first: “We will deal with audits later.” But the risk compounds. The common failure modes:
- Audit failure: Regulator asks for end-to-end lineage of a customer record. You cannot produce it within the response window. Penalty plus remediation.
- Shadow data: Datasets multiply across workspaces. Nobody knows which is canonical. Decisions get made on the wrong copy.
- PII leakage: A column flagged as
customer_emailends up in a public-facing dashboard because no classification policy was applied at ingestion. - Pipeline blindness. Production pipeline breaks. Nobody can identify which downstream reports are affected. Customers find out before you do.
- Migration paralysis. When you eventually try to move to a new platform, you cannot, because nobody understands the current data estate.
Failure-Mode Iceberg waterline (what’s visible) Audit notice the only thing leadership sees Audit failure (no lineage to produce) Shadow data (canonical copy unknown) PII leakage (no ingest-time labels) Pipeline blindness (no impact map) Migration paralysis (estate unknown)
these failures are interconnected and accelerating, long before anyone sees them.

Figure 8 — The audit notice is the tip. Below the waterline, five failure modes are already interconnected and accelerating.
The smarter path is to tackle governance alongside your migrations, to build the bridge from Day 1. Governance becomes part of your data operating system, not a retrofit.
11. Before You Build: The Pre-Engineering Foundation
This is Article 1 for a reason. Before you provision a single Azure resource or configure a single IR, there is foundational work that separates a governance project that sticks from one that gets abandoned in a month. Everything below is what you need to know, plan, and align on before opening the Azure portal.
11.1 Step 1. Assess Your Governance Maturity
You cannot fix what you have not measured. Most organizations sit at one of four levels:
- Level 1 — Ad hoc — Tribal knowledge, no catalog, no classification (“ask Sanjay”).
- Level 2 — Tooled but siloed — Multiple tools (catalog, DLP, classifier), no integration.
- Level 3 — Integrated (POC target) — Purview deployed, Unity Catalog scanned, lineage and DLP active.
- Level 4 — Automated — Policies in CI/CD, governance as code, automated remediation.
Most teams start at Level 1 or 2. This series is designed to move you to Level 3. Be brutally honest about where you are.
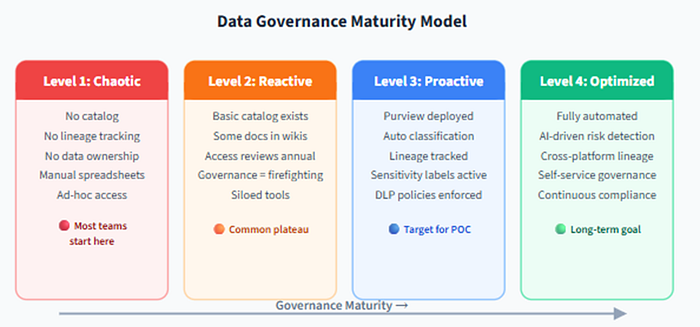
Figure 9 — Most teams start at Level 1 or 2. The goal of this article series is to get you to Level 3. Level 4 is a separate maturity journey.
11.2 Step 2. Map Your Regulatory Landscape
Before configuring a single policy, you need to know which rules you are playing by. Different industries face different mandates, and Purview’s compliance templates map directly to them.
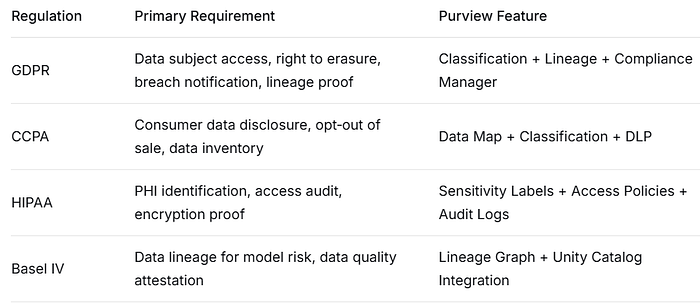
Once you have identified which regulations apply, use Purview Compliance Manager to generate a regulatory assessment. It produces a compliance score and a prioritized action list, so you are not guessing what to tackle first.
11.3 Step 3. Align Your Stakeholders (Where Most POCs Die)
Governance projects do not fail because of technology. They fail because nobody aligned the right people before Day 1. You need buy-in from three groups, and each cares about something different.
The Three-Stakeholder Pitch Triangle Engineering pipeline reliability, scan performance, low ops burden Compliance audit readiness, regulatory mapping, evidence trails Business speed to insight, trust in dashboards, self-service growth “eliminates manual lineage work” “self-service with confidence” “audit-ready by button click”
each pair shares one edge, one common interest. each vertex needs a different pitch.

Figure 11. Each stakeholder group needs a different pitch. Walk in with one generic deck and you will lose two of the three.
Schedule a one-hour alignment meeting with representatives from all three groups before any technical work begins. Walk through the maturity assessment, the regulatory mapping, and agree on a shared definition of “success” for the POC. Without this, you will build something nobody adopts.
11.4 Step 4. Make Your Architecture Decisions Upfront
Before provisioning resources, answer these. Getting any wrong means rework later:
- Integration Runtime type. Azure IR, Managed VNet IR, or Kubernetes SHIR? Decided by Databricks network exposure and corporate policy.
- Single-region or multi-region? Unity Catalog metastores are per-region. Cross-region governance needs deliberate design.
- Public endpoint or Private Link? This drives the IR choice and adds 2 to 5 days of network engineering.
- Scan scope and frequency. Full vs incremental, daily vs hourly, scoped to which catalogs?
- Tenant model. Single Purview account for the whole org, or per-business-unit?
- Classification ruleset. Microsoft’s defaults, custom rules, or both?
11.5 Step 5. Define Roles and Responsibilities
Governance without ownership is documentation nobody reads. Before starting, assign these explicitly.

11.6 Step 6. Azure Resources and Prerequisites
A typical enterprise POC requires 3 to 5 days of platform engineering for initial setup, and 2 to 3 weeks for full integration including network configuration and security review. The provisioning checklist:
- Azure subscription with
Contributoror higher at the resource-group level - Microsoft Purview account (one per tenant, usually)
- Azure Databricks workspace with Unity Catalog enabled and a metastore attached
- Azure Key Vault in the same region (recommended)
- Integration Runtime. Azure IR (zero infra), Managed VNet IR (managed PE), or a Kubernetes SHIR if neither fits
- Databricks SQL Warehouse (the Starter warehouse is fine for POC)
system.accessschema enabled in Unity Catalog (required for lineage)- JDK 11 on the runtime host only if you are using a self-hosted IR
Required permissions (grant these before the first scan)
- Purview.
Data Source AdministratorplusData Readerfor the engineer running the registration - Databricks. A user or service principal with
USE CATALOG,USE SCHEMA,SELECTon target objects, plusSELECTon thesystem.accesslineage tables - Key Vault. Purview Managed Identity needs
GetandListon secrets - Networking. Outbound HTTPS from the IR to (a) the Databricks workspace URL, (b) the Key Vault endpoint, and © the Purview ingestion endpoint
Missing any of these blocks your first scan, and the failure mode is usually a silent “no results.
11.7 Step 7. Plan Your Network Topology
This is where POCs most often get stuck. The IR needs to reach three endpoints. If any is blocked, your scans fail silently.
Network Reachability Map Integration Runtime Databricks workspace *.azuredatabricks.net HTTPS / 443 Azure Key Vault *.vault.azure.net HTTPS / 443 Purview ingestion *.purview.azure.com HTTPS / 443, All three required Miss one and the scan fails silently. Usually weeks pass before anyone notices.
use Private Endpoints for production; Service Tags simplify firewall rules
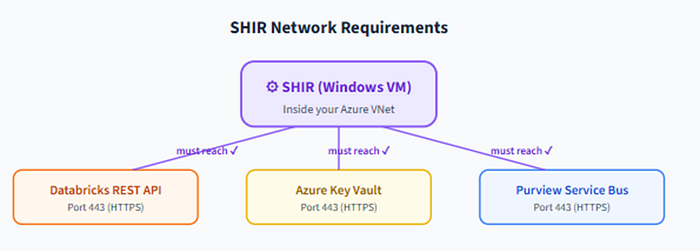
Figure 12. Three endpoints, all reachable from the IR. Miss one and the scan fails silently, usually weeks before anyone notices.
11.8 Step 8. Define POC Scope and Success Criteria
The biggest mistake teams make: trying to govern everything in the POC. Don’t.
Recommended POC scope. Pick one business domain (for example, customer data or financial reporting) with 5 to 10 tables across 2 to 3 pipelines. Enough to validate the full flow (scanning, classification, lineage, labeling, DLP) without boiling the ocean.
Measurable success criteria (template):
- 100% of in-scope tables appear in the Purview Data Map within 24 hours of creation
- At least 95% of in-scope columns containing PII are auto-classified correctly
- Column-level lineage exists for every in-scope pipeline
- At least one sensitivity label is applied and propagates downstream
- A simulated GDPR Subject Access Request can be answered with lineage evidence in under 1 hour
- Compliance Manager shows a baseline score for at least one regulatory template (GDPR, HIPAA, or BCBS 239)
11.9 Step 9. Realistic POC Timeline
Four-Week POC Plan Week 1 Week 2 Week 3 Week 4
Planning Build Configure Validate Demo / Go-live
maturity, regs, stakeholders provision + IR + Key Vault scan + classify + lineage success criteria check demo + go/no-go Week 1 is entirely non-technical. That is deliberate. The planning saves you weeks of rework later.
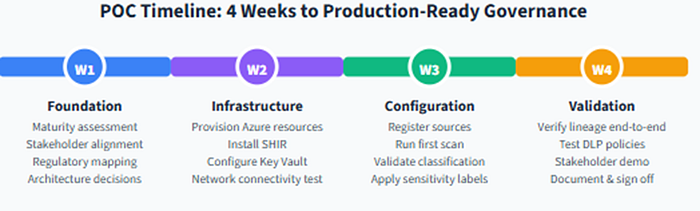
Figure 13. A realistic four-week POC. Week 1 is entirely non-technical, and that is deliberate.
The planning and alignment work in Week 1 is the hidden cost most teams skip, and exactly why this Part 1 exists.
12. What This Article Does Not Cover (Yet)
This article is the theory and planning foundation. We deliberately stopped before the hands-on engineering. Here is what is coming:
- Article 2. Hands-On Build. Resource provisioning, IR setup, Key Vault wiring, Unity Catalog scan configuration, classification rules, custom lineage, scheduled scans, and runbooks. No theory, all engineering.
- Article 3. AI Workflows on Governed Metadata. Using Purview metadata as grounding for LLM applications, classification-aware retrieval, AI risk controls (model registries, sensitivity-aware prompts), and how to surface Purview signals inside copilots and agent frameworks.
13. Final Thoughts
There is a moment in every governance project that I call the Clarity Point on the moment when you run your first successful Purview scan, see your Unity Catalog tables appear in the Data Map, and watch lineage edges draw themselves across the screen connecting pipelines you built months ago. It feels different from any other infrastructure milestone. It feels like the data estate you built, but didn’t fully know, finally becoming visible to you.
That visibility is worth more than it looks. It is the difference between a compliance team that trusts your data and one that audits it on a quarterly basis. It is the difference between a data scientist who can pull a feature with confidence and one who has to ask three people whether the column is safe to use. It is the difference between an AI model whose training data you can defend and one whose lineage you cannot reconstruct.
Microsoft Purview and Databricks Unity Catalog give you the tools to build that visibility. But the technology is the easy part — the planning, alignment, maturity assessment, and architectural decisions you make before writing a single line of configuration are what determine whether it sticks.
This article gave you the why, the what, and the who. Article 2 gives you the how.
The Question to Take Into Your Next Sprint:
The next time you spin up a new Delta table, add a column to an existing pipeline, or onboard a new data source: pause and ask “Who inherits this governance debt if we don’t document it now? And in 18 months, when compliance asks for lineage, what will our answer be?”
If your answer involves the phrase “we’ll figure it out then,” you are accumulating debt at compound interest. Start the bridge today.
This article gave you the blueprint. Article 2 gives you the build. Hands-on. Step-by-step. Command-by-command. The entire Databricks–Purview bridge, provisioned from an empty Azure subscription to a live lineage graph — no theory, just engineering.
References
- Microsoft Purview — Official Documentation
- Microsoft Purview — Register and scan Azure Databricks Unity Catalog
- Databricks Unity Catalog — Getting Started Guide
- Databricks REST API Reference
- Azure Key Vault Documentation
- Microsoft Purview Compliance Manager
- Microsoft Fabric — Documentation
- OpenLineage — Open Standard for Data Lineage
- GDPR Overview — European Commission Portal
- GDPR Fines and Penalties Tracker
- CCPA — California Attorney General
- Basel IV Framework — Bank for International Settlements
- EU AI Act — Official Tracker
- Databricks Community Forums
- Microsoft Tech Community — Security Blog
Comments
Loading comments…