In my last post, we saw how we turn messy PDFs into a “Smart Filing Cabinet” (a Vector Database). But how does the AI actually use that cabinet to talk to you?
In the previous article, we learned how data is prepared and stored during the Ingestion Stage. Now, let’s explore the Inference Stage, where the AI finds relevant information and uses it to answer questions.
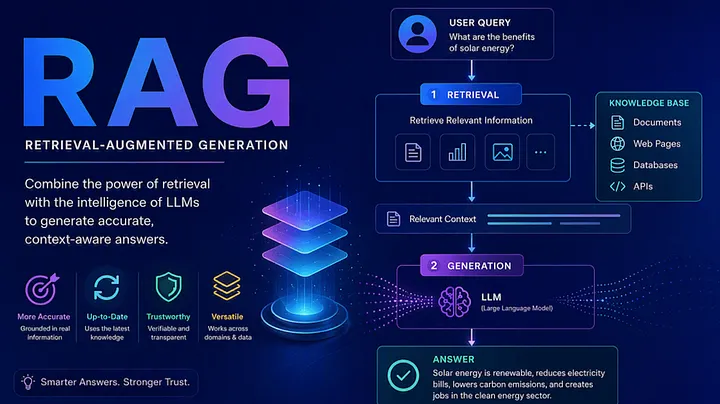
In simple terms: RAG allows AI to “look up” information from your documents before answering, instead of relying only on what it learned during training.
Think of RAG as the “Open-Book Exam” for AI. Instead of the AI answering from its own memory, it follows a 3-step loop:
- Retrieve: When you ask, “What is our remote work policy?”, the system doesn’t guess. It turns your question into math and “runs” into your Vector Database to grab the most relevant chunks of information.
- Augment: The system “glues” those facts to your question. It creates a prompt that says: “Using ONLY these facts from the manual, answer the user’s question.”
- Generate: The AI “Brain” reads the facts and writes a human-sounding response. Because it has the source right in front of it, it doesn’t have to rely on training data from two years ago.
The Evolution: Not All RAG is Created Equal
As I’ve been diving deeper into LangChain, I’ve realized that RAG is leveling up. Here are the 4 key types of RAG architectures being used today:
- Standard RAG (The Librarian): Finds a paragraph and summarizes it. Perfect for simple FAQs.
- Conversational RAG (The Memory): Keeps track of “Chat History” so you can ask follow-up questions without repeating yourself.
- Corrective & Agentic RAG (The Self-Checker): The AI evaluates the documents. If the info is poor, it searches the web or critiques its own response before showing it to you.
- GraphRAG (The Deep Thinker): Connects the dots across hundreds of documents to find relationships between ideas, not just keywords.
RAG is the bridge between a “General AI” and a “Company Expert.” It’s how we move from AI that is fun to talk to to AI that is safe to work with.
For those who want to see the actual “blueprints” of these architectures, I’ve attached a map below. It shows the transition from the core pipeline to specialized versions like HyDE, Hybrid, and Adaptive RAG.
Comments
Loading comments…