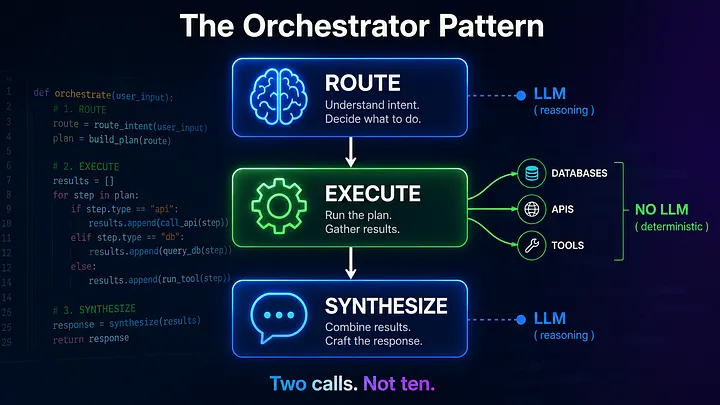
Route once. Execute deterministically. Synthesize once. Two LLM calls instead of ten — and your system becomes predictable, fast, and debuggable.
In the previous article, we built an agentic loop: a while loop where the LLM decides what to do, executes a tool, observes the result, and decides again. That pattern works — until you look at the bill.
A three-agent query through an agentic loop: 7 LLM calls, 4.2 seconds, $0.12. The same query through an orchestrator: 2 LLM calls, 1.1 seconds, $0.03. Same agents, same answer, 70% cheaper.
Every iteration of the loop is an LLM call. Each call adds 300–800ms of latency and costs money. For a simple “call check_greeting, then call handle_hi” — two LLM calls for routing is fine. But the moment you need to:
- Call three agents in parallel for a single answer
- Execute a sequential plan where step 2 depends on step 1
- Handle hundreds of queries per second in production
…the agentic loop breaks down. The LLM is in the critical path for every single decision, and every decision adds latency.
The fix: ask the LLM once for the plan, then execute without it.
The Orchestrator Pattern: Two Calls, Not Ten
Here is the entire architecture in three steps:
User Query
↓
[STEP 1: ROUTE] ← ONE LLM call: "which agents should handle this?"
↓
[STEP 2: EXECUTE] ← NO LLM: call agents deterministically
↓
[STEP 3: SYNTHESIZE] ← ONE LLM call: "write a nice answer from these results"
↓
Final Answer
The LLM touches the request exactly twice — once to decide the plan, once to format the answer. Everything in between is your application executing code. No loops. No uncertainty. No “will the LLM decide to call another tool?”
Compare this to the agentic loop:

What We Are Building
An orchestrator that handles three types of queries:
- Single agent — “What are the current system metrics?” → route to one agent
- Parallel fan-out — “Get me the metrics and the trend analysis” → call two agents simultaneously
- Sequential DAG — “Check for anomalies, then if found, pull the config for that component” → call agents in order with dependencies
Same agents, same tools — but the LLM makes one routing decision and the application handles execution.
The Agent Registry: A Phone Book, Not a Discovery Protocol
Agents register their capabilities in a simple dictionary. No discovery protocol needed — you deployed these agents, you know what they do:
REGISTRY = {
"data_agent__get_report": {
"agent": "Data Agent",
"description": "Fetch the latest report for a given entity",
"execute": get_report, # Python function (or HTTP endpoint in prod)
},
"analytics_agent__get_trends": {
"agent": "Analytics Agent",
"description": "Get historical trends and anomaly detection",
"execute": get_trends,
},
"config_agent__check_config": {
"agent": "Config Agent",
"description": "Check system configuration for a given component",
"execute": check_config,
},
}
In production, this registry lives in Redis or a database, and agents register via HTTP POST. The pattern is identical — a lookup table from skill name to execution function.
The LLM sees these agents as tool definitions (JSON schemas). But the key trick is a fourth meta-tool:
{
"name": "plan_execution",
"description": "Use this ONLY when the query requires sequential steps "
"where a later step DEPENDS on the result of an earlier step.",
"parameters": {
"properties": { "reason": {"type": "string"} },
"required": ["reason"]
},
}
plan_execution doesn’t call an agent — it does nothing at all. That is the trick. It is a signal, not a function. When the LLM picks it, the orchestrator knows to switch to sequential mode. One LLM call, one set of tool choices, three possible execution strategies — single, parallel, or sequential — all determined by which tools come back.
Step 1: The Router — One LLM Call to Rule Them All
The router makes one LLM call with temperature=0.0 (deterministic). The LLM’s only job: pick tool(s). It is explicitly told not to answer the question.
SYSTEM_PROMPT = """You are a query router. Your ONLY job is to decide which tool(s) to call.
Rules:
- If the query needs ONE agent, call that one tool.
- If the query needs MULTIPLE INDEPENDENT agents, call all of them.
- If the query needs steps IN ORDER, call plan_execution.
Do NOT answer the user's question — just pick tools."""
The single LLM call:
response = client.chat.completions.create(
model=deployment,
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": query}],
tools=TOOL_DEFINITIONS,
tool_choice="auto",
temperature=0.0, # Deterministic — same query → same routing
)
Then interpret the response — this is the entire routing logic:
tool_names = [tc.function.name for tc in reply.tool_calls]
if "plan_execution" in tool_names: → mode = "sequential"
elif len(tool_names) == 1: → mode = "single"
else: → mode = "parallel"
The LLM returns structured tool calls, not text. One tool → single. Multiple tools → parallel. The plan_execution meta-tool → sequential. One call, three execution strategies.
Step 2: The Executor — No LLM Here
This is where the orchestrator pattern pays off. The executor is pure Python — no LLM, no uncertainty, no latency surprises. Three modes:
- Single — just call the agent:
result = REGISTRY[tool_name]["execute"]()
- Parallel — call all agents simultaneously:
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = {name: pool.submit(REGISTRY[name]["execute"]) for name in tool_names}
results = {name: f.result() for name, f in futures.items()}
- Sequential — call agents in order, passing context forward:
for step in plan:
results[step["tool"]] = REGISTRY[step["tool"]]["execute"]()
Zero LLM involvement. In production, these would be asyncio.gather with HTTP calls to real agent endpoints.
This is the architectural win: after routing, your system behaves like any other microservice orchestration. Predictable latency, straightforward debugging, standard observability. The “AI” part is confined to two thin layers (routing and synthesis) with deterministic execution in between.
Step 3: The Synthesizer — Polish the Answer
Raw agent results are JSON. Users want natural language. One more LLM call turns data into a response:
response = client.chat.completions.create(
model=deployment,
messages=[
{"role": "system", "content": "Summarize the agent results into a clear, helpful answer."},
{"role": "user", "content": f"User asked: {query}\nResults: {json.dumps(results)}"},
],
temperature=0.7, # Creative — readability matters here
)
Notice: temperature=0.7 here (creative), versus 0.0 in the router (deterministic). Routing needs precision. Synthesis needs readability. Different jobs, different settings.
Putting It Together: Three Queries, Three Modes
The full pipeline is just three function calls:
decision = route_query(client, deployment, query) # LLM call #1
results = execute(decision) # No LLM
answer = synthesize(client, deployment, query, results) # LLM call #2
- Query 1 — Single: “What are the current system metrics?” → Router picks data_agent__get_report → executor calls it → synthesizer writes a human-readable summary.
- Query 2 — Parallel: “Get me the metrics and the trend analysis” → Router picks both agents → executor calls them simultaneously → synthesizer merges both results into one answer.
- Query 3 — Sequential: “Check for anomalies, then if found, pull the config for that component” → Router picks plan_execution → executor runs analytics first, then config → synthesizer explains the chain.
Same pipeline, three execution strategies, always exactly two LLM calls.
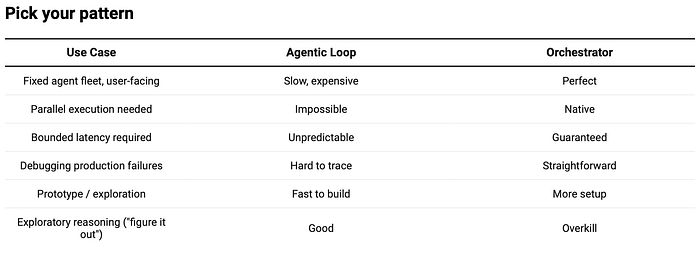
Agentic Loop vs. Orchestrator: When to Use Which
The Architectural Insight
The agentic loop treats the LLM as both brain and hands — it decides AND executes on every step. The orchestrator separates concerns:
- LLM = Brain → Makes the plan (one call)
- Application = Hands → Executes the plan (deterministically)
- LLM = Mouth → Explains the result (one call)
This separation is why the orchestrator scales. The “brain” part (routing) can be cached — same query always gets same routing at temperature=0.0. The “hands” part (execution) is just HTTP calls. The “mouth” part (synthesis) is the only creative step.
In production, you can even skip synthesis for API consumers who want raw JSON — reducing to one LLM call per request.
The Bottom Line
The agentic loop is the right pattern for exploration. The orchestrator is the right pattern for production.
If you already know which agents exist and what they do — and you need bounded latency, parallel execution, and debuggable request flows — stop putting your LLM in a loop. Ask it once. Execute. Synthesize. Done.
Two calls. Not ten.
This is Part 2 of the series. Part 1 covered the agentic loop pattern. Together, these two patterns cover 90% of production AI agent architectures.
Comments
Loading comments…