Version control solved software history. Now it might solve AI memory.
Here’s something nobody tells you about Git.
Git doesn’t care about code.
It never did.
Every commit you’ve ever made — every git commit -m "fix stuff" at 11pm — wasn't really about the code. It was about capturing a decision. The moment you chose one approach over another. The moment you deleted something and said: this is no longer how I think.
The code was just the artifact. The commit was the memory.
Now ask yourself: if an AI agent is nothing more than a chain of decisions… what happens when Git starts remembering those instead?
Git Was Never About Code
Think about what a commit actually is.
It’s not a file. It’s not even a diff, not really. A commit is a snapshot of intent at a specific point in time. It says: here is what we believed was correct, on this date, given what we knew then.
A diff shows you what changed. A commit tells you why someone thought it needed to change.
That distinction sounds small. It isn’t.
When you run git blame, you're not looking for who wrote a line. You're asking: who made this decision, and when? When you run git log, you're not reading file history. You're reading the evolution of someone's thinking.
Git is a timeline of reasoning disguised as a version control system.
For twenty years, we’ve been using it to record how software evolves. The strange part? We barely noticed we were building the perfect substrate for something else entirely.
The Problem with How AI Agents Remember Today
Modern AI agents have a memory problem that nobody talks about honestly.
They forget. Almost everything. Almost immediately.
An LLM-based agent can plan a task, call a tool, receive a response, reason about the next step — and unless you’ve explicitly engineered some form of persistence, that reasoning evaporates the moment the context window closes. Each session starts over. The agent that failed at something yesterday has no idea it failed.
Developers have reached for databases. Vector stores. Redis. Knowledge graphs. Embedding layers that surface “similar” past experiences.
These solutions work, sort of. But they share a critical flaw: they store what the agent knew, not how the agent thought.
A database can tell you that an agent retrieved a document about quarterly earnings. It can’t tell you why the agent decided that document was relevant, what it concluded, whether that conclusion was correct, or when exactly its reasoning started to degrade.
Data is not thinking. Storage is not memory.
What If Every Reasoning Step Became a Commit?
Here’s the idea that won’t leave me alone.
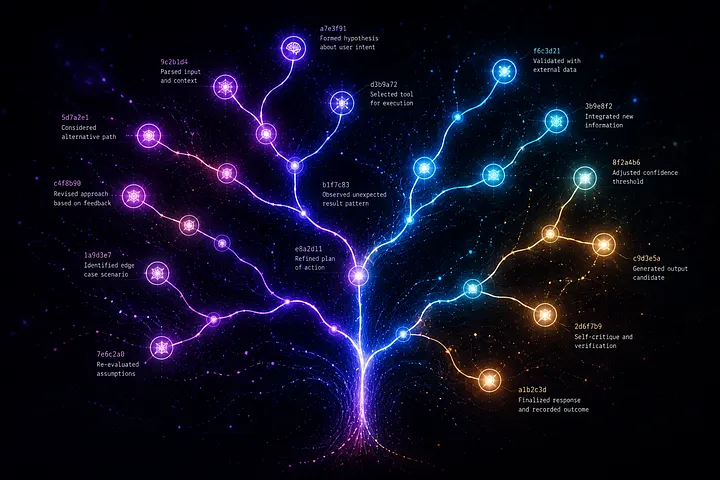
Imagine an agent working through a complex task. Not just storing its outputs in a database — but committing its reasoning states like a developer commits code.
commit a3f9b12
Author: agent-7 <agent-7@system>
Date: Tue Jun 10 14:22:01 2025
Chose search tool over cached knowledge
Confidence in cached context was low (0.61).
Web search selected for freshness.
commit b82cc47
Author: agent-7 <agent-7@system>
Date: Tue Jun 10 14:22:18 2025
Search results ambiguous - switched strategy
First three results contradicted each other.
Falling back to structured reasoning before next tool call.
commit 1d4e90a
Author: agent-7 <agent-7@system>
Date: Tue Jun 10 14:23:05 2025
Hallucination detected and corrected
Stated a figure that wasn't in source material.
Evaluator flagged. Rerunning with citation requirement.
Every decision. Every failure. Every course correction. Every moment the agent changed its mind.
Committed.
This isn’t science fiction. It’s a design pattern waiting to be named.
Debugging Intelligence Like We Debug Code
When a system breaks, developers open git log and start reading backwards.
What changed? When did it change? Who changed it? Why did that change cause this outcome?
Now imagine applying that same workflow to an AI agent that started producing wrong answers three weeks ago.
Which commit introduced the drift? Was it a prompt change? A tool update? A shift in the agent’s learned preferences? You’d be able to run git diff on reasoning behavior the same way you diff source code.
Questions that currently have no good answers would suddenly have exact ones.
Why did the agent choose this API over that one? Check the commit. When did it stop citing sources correctly? Bisect the history. Who changed the evaluator prompt, and what effect did that have on output quality? git blame tells you.
This reframes something important: right now, AI debugging is mostly vibes. You notice the agent is worse. You don’t know exactly when or why. You try things and see if they help.
Git-native agent memory would turn that guesswork into archaeology.
The Possibilities Starting to Emerge
Nobody has fully built this yet. But pieces of it are appearing in different places, quietly.
Memory branching. An agent could maintain separate branches for different hypotheses — exploring one reasoning path while keeping another intact. If the branch fails, you don’t lose the main line of thought. You checkout and try again.
Rollback. If an agent’s behavior degrades after a configuration change, you roll back its memory state the same way you roll back a bad deploy. No retraining. No starting from scratch. Just git revert.
Forking personalities. A base agent could be forked for different domains — one branch specializing in legal reasoning, another in technical analysis — while sharing a common ancestry of foundational behavior.
Merging experience. Two agents working on separate tasks could merge their learned reasoning, the same way two developers merge branches. Conflicts would need resolution. Insights could compound.
Reproducibility. Pin an agent to a specific commit hash before a critical task. Anyone who needs to audit the reasoning later can check out that exact state.
These aren’t features of a product. They’re natural consequences of treating agent memory like source code.
Could Git Become the Operating System for Agent Memory?
Think about what Git already gives you for free.
History: every state that ever existed, preserved and addressable. Identity: who made what change and when. Diffs: exactly what shifted between two states. Branches: parallel timelines that don’t interfere with each other. Rollback: the ability to undo any change without losing the record that it happened. Collaboration: multiple contributors working on the same codebase with conflict resolution built in.
Now say those words again, but replace “codebase” with “intelligence.”
Every property that makes Git powerful for software becomes interesting — and possibly load-bearing — when applied to AI agents trying to learn and persist across time.
We didn’t design Git for this. But then again, we didn’t design the internet for video streaming or smartphones for replacing cameras. The best tools have a way of finding uses their inventors never imagined.
Git’s data model — immutable snapshots, content-addressed storage, directed acyclic graphs — happens to be a near-perfect fit for recording how a thinking system evolves. That’s not an accident. That’s just good architecture being useful in ways nobody expected.
What Comes Next
I don’t think Git will replace the memory systems being built for AI agents today.
But I do think the ideas in Git — provenance, history, branching, diffing, rollback — are going to become foundational vocabulary for how we build AI systems that remember, learn, and can be trusted.
Right now, when an AI agent makes a bad decision, we have almost no way to understand why. We retrain. We re-prompt. We hope.
The developers who figure out how to give agents a real history — not just a log, but a versioned, branchable, diffable record of how they reasoned — are going to build something genuinely different from everything that exists today.
For twenty years, we committed code.
Maybe the next twenty will be about committing thought.
The tools were always there. We just hadn’t imagined what else they could hold.
Comments
Loading comments…