Are you ready to supercharge your Python web development with the perfect combination of SQLAlchemy and Supabase? In this comprehensive guide, we’ll walk you through the steps to set up Supabase, install the necessary dependencies, and seamlessly integrate SQLAlchemy into your Python workflow. We’ll explore both the Core and Object-Relational Mapping (ORM) approaches in SQLAlchemy, providing you with the tools and knowledge to elevate your database interactions. Let’s dive into the world of Python web development, powered by SQLAlchemy and Supabase.

Setup Supabase
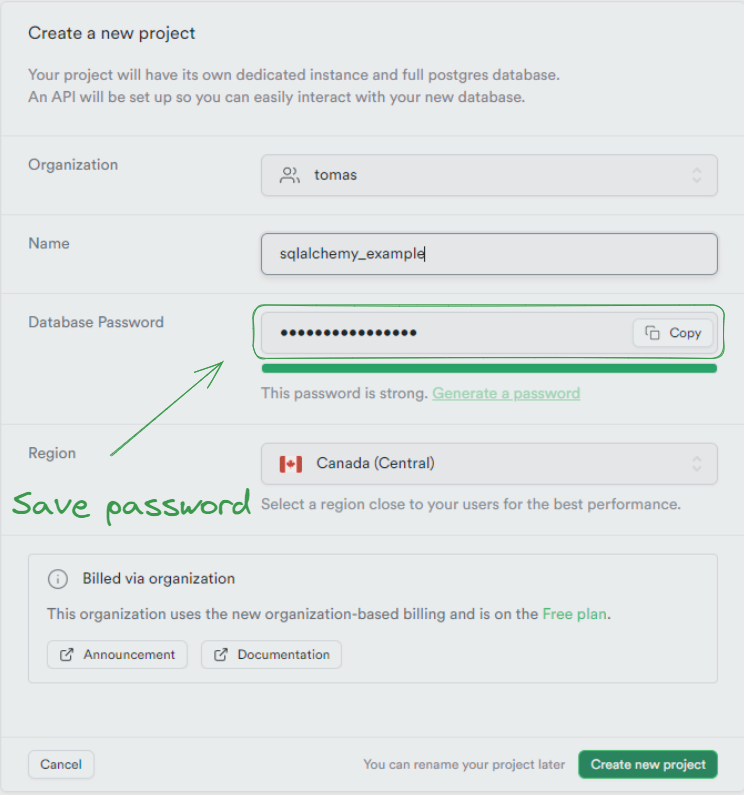
Step 1
First, we need to create an important step: saving the password for later use.
Step 2
After that, we need to go to the settings and check for the credentials we have. These will be needed in the code for the database connection.

That wraps up Supabase. It was easy, right? Now, let’s dive into Python.
Install dependencies
pip install psycopg2-binary
pip install SQLAlchemy
pip install python-dotenv
SQLAlchemy
In SQLAlchemy, there are two primary approaches to working with databases: Core and ORM.
Core:
- The Core approach is akin to a query builder. It allows you to construct and execute SQL queries in a programmatic way. This means you can write and execute raw SQL statements using Python. The core is powerful and flexible, making it a suitable choice for scenarios where you need fine-grained control over your database interactions. It’s especially useful when you have complex queries or need to optimize database performance.
ORM (Object-Relational Mapping):
- ORM, on the other hand, extends the Core version by introducing the concept of mapping objects to database tables. This means you can work with Python objects that represent database records, making it a more Pythonic and object-oriented approach to database interactions. With ORM, you define your database schema using Python classes, and the library takes care of translating your Python code to SQL queries. This simplifies database interactions, as you can work with Python objects rather than dealing directly with SQL. ORM is a popular choice for applications where you want to work with data in an object-oriented manner and reduce the amount of SQL code you write.
So, in summary, Core and ORM are both valuable approaches in SQLAlchemy, with Core offering flexibility and control, while ORM provides a more Pythonic and object-oriented way of working with databases.
Initial code
First, we will prepare the code for establishing a database connection. You’ll notice that there are separate code sections for Core and ORM approaches in SQLAlchemy.
SQLAlchemy allows us to create database tables from code definitions, but the process differs between these two approaches.
In the ORM approach, things work a bit differently. Here, we use a session. A Session serves as an intermediary between your program and the database. It manages all interactions with the database and acts as a container for Python model objects. When working with ORM, you load your Python model objects into a session, and it handles the communication with the database for you.
# db.py
from sqlalchemy import create_engine, MetaData
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from dotenv import dotenv_values
metadata = MetaData()
Base = declarative_base()
def db_connect():
config = dotenv_values("./.env")
username = config.get("DATABASE_USERNAME")
password = config.get("DATABASE_PASSWORD")
dbname = config.get("DATABASE_NAME")
port = config.get("DATABASE_PORT")
host = config.get("DATABASE_HOST")
engine = create_engine(f"postgresql+psycopg2://{username}:{password}@{host}:{port}/{dbname}", echo=True)
connection = engine.connect()
return engine, connection
def create_tables(engine):
metadata.drop_all(engine, checkfirst=True)
metadata.create_all(engine, checkfirst=True)
def create_tables_orm(engine):
Base.metadata.drop_all(engine, checkfirst=True)
Base.metadata.create_all(engine, checkfirst=True)
def create_session(engine):
Session = sessionmaker(bind=engine)
session = Session()
return session
# .env
DATABASE_HOST=db.rsvxhkzwvmxbbqfifbsx.supabase.co
DATABASE_USERNAME=postgres
DATABASE_PASSWORD=sji8h5UPte4Knx89
DATABASE_NAME=postgres
DATABASE_PORT=5432
Note
echo=True is included for development purposes, allowing us to see in the console the queries that have been executed. It's a valuable tool for monitoring what's happening under the hood.
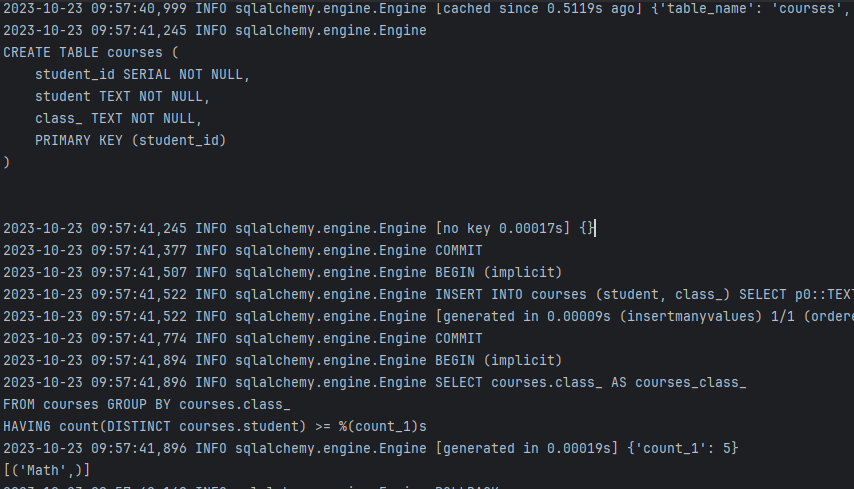
Console output
Project structure
Project files
Original SQL
We want to transform this SQL code into Python code
CREATE TABLE courses (
student_id bigserial PRIMARY KEY,
student TEXT NOT NULL,
class TEXT NOT NULL
);
INSERT INTO courses (student, class) VALUES
('A', 'Math'),
('B', 'English'),
('C', 'Math'),
('D', 'Biology'),
('E', 'Math'),
('F', 'Computer'),
('G', 'Math'),
('H', 'Math'),
('I', 'Math');
SELECT
class
FROM
courses
GROUP BY class
HAVING COUNT(DISTINCT student) >= 5;
Core Approach
First, we need to define a table using the Table class and create the table using the code from the previous step. To ensure that we avoid errors, we use checkfirst to verify if the table already exists.
Next, we populate our database with data. We achieve this by calling execute on the connection object. It's essential to follow this up with a commit operation; this is crucial because, without it, the changes won't be saved to the database.
from sqlalchemy import Table, Column, Integer, Text, func, select, distinct, insert
from db import db_connect, create_tables, metadata
engine, connection = db_connect()
course = Table(
"courses",
metadata,
Column("student_id", Integer, primary_key=True),
Column("student", Text, nullable=False),
Column("class", Text, nullable=False),
)
create_tables(engine)
new_courses = [
{"student": "A", "class": "Math"},
{"student": "B", "class": "English"},
{"student": "C", "class": "Math"},
{"student": "D", "class": "Biology"},
{"student": "E", "class": "Math"},
{"student": "F", "class": "Computer"},
{"student": "G", "class": "Math"},
{"student": "H", "class": "Math"},
{"student": "I", "class": "Math"},
]
connection.execute(insert(course), new_courses)
connection.commit()
query = (
select(course.c["class"])
.group_by(course.c["class"])
.having(func.count(distinct(course.c.student)) >= 5)
)
result = connection.execute(query)
print(result.all()) # [('Math',)]
connection.close()
ORM Approach
It’s similar to the previous example, but here, instead of using the Table class, we work with classes directly and inherit from the base. After that, we interact with the session.
from sqlalchemy import Column, Integer, Text, func, distinct
from db import db_connect, create_session, Base, create_tables_orm
engine, connection = db_connect()
session = create_session(engine)
class Course(Base):
__tablename__ = "courses"
student_id = Column(Integer, primary_key=True)
student = Column(Text, nullable=False)
class_ = Column(Text, nullable=False)
create_tables_orm(engine)
new_courses = [
Course(student="A", class_="Math"),
Course(student="B", class_="English"),
Course(student="C", class_="Math"),
Course(student="D", class_="Biology"),
Course(student="E", class_="Math"),
Course(student="F", class_="Computer"),
Course(student="G", class_="Math"),
Course(student="H", class_="Math"),
Course(student="HI", class_="Math"),
]
session.add_all(new_courses)
session.commit()
result = (
session.query(Course.class_)
.group_by(Course.class_)
.having(func.count(distinct(Course.student)) >= 5)
)
print(result.all()) # [('Math',)]
session.close()
connection.close()
Thanks for reading my article!
If you enjoyed the read and want to be part of our growing community, hit the follow button, and let’s embark on a knowledge journey together.
Your feedback and comments are always welcome, so don’t hold back!
Comments
Loading comments…