
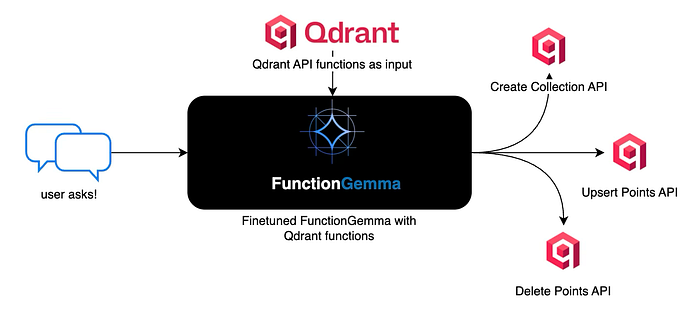
This article is written for builders who want language models to do something concrete, not just respond with text. When models are connected to real systems like databases or APIs, reliability and structure matter more than fluent language. In this article ahead, we walk through a hands-on implementation that trains FunctionGemma to convert natural language into valid Qdrant actions. The goal is simple: show how a small model can be shaped into a predictable execution layer that works locally and fits naturally into real agent systems.
What is FunctionGemma?
FunctionGemma represents a shift in how small language models are used inside real systems. Instead of treating a model as a conversational endpoint, FunctionGemma positions the model as an execution-oriented component that understands intent and converts it into concrete actions. Built on top of the Gemma 3 270M lineage from Google, it focuses on precision, structure, and reliability rather than open-ended language generation.
What makes FunctionGemma stand out is its alignment with software boundaries. It operates within a known action space and produces outputs that are directly consumable by code. This makes it far more suitable for environments where a language model is expected to trigger APIs, invoke system capabilities, or control application workflows. Instead of guessing what to do with text, the system receives intent that is already shaped for execution.
Another important dimension is customization. FunctionGemma is not designed to be used as-is for every use case. Its real value emerges when it is fine-tuned with domain-specific data. This allows teams to encode business logic, constraints, and preferences directly into the model. The result is behavior that is repeatable and predictable, which is essential when language is used as an interface to production systems.
Local execution is a natural fit for this design. Because FunctionGemma is compact and efficient, it can be finetuned and run close to the user on edge devices or private infrastructure. This enables low-latency interactions and keeps sensitive data within trusted boundaries. For many applications, this removes the need to depend on remote inference while still benefiting from natural language control.
What are we going to finetune?
The intention of this model training is to show how a small, execution-oriented language model can be trained to convert natural language instructions into structured Qdrant API calls. The focus is not on conversation quality, but on correctness, determinism, and tool execution, using FunctionGemma as the decision layer and Qdrant as the target system.
!pip install torch transformers datasets accelerate evaluate trl protobuf sentencepiece huggingface-hub
The above code installs all the essential Python packages required for fine-tuning the language model. The torch package provides the deep learning framework, transformers enables loading and working with pre-trained models from HuggingFace, datasets facilitates data handling and preprocessing, accelerate optimizes training on various hardware configurations, evaluate offers metrics for model assessment, trl provides the supervised fine-tuning trainer, while protobuf and sentencepiece handle tokenization for the Gemma model family, and huggingface-hub manages model versioning and downloading.
base_model = "google/functiongemma-270m-it"
learning_rate = 5e-5
This code establishes the fundamental training parameters by setting the base model identifier to Google’s FunctionGemma 270M instruction-tuned variant, which is specifically designed for function calling tasks, and configures the learning rate to 5e-5, a relatively conservative value that ensures stable training without overshooting optimal weight updates during gradient descent.
qdrant_tool_calling = [
{"user_content":"Create a new collection called documents with 384 dimensional vectors using cosine distance","tool_name":"create_collection","tool_arguments":"{\"collection_name\": \"documents\", \"vector_size\": 384, \"distance\": \"Cosine\"}"},
{"user_content":"Add a point with id 1 to the images collection with vector [0.5, 0.3] and metadata category cat","tool_name":"upsert_points","tool_arguments":"{\"collection_name\": \"images\", \"points\": [{\"id\": 1, \"vector\": [0.5, 0.3], \"payload\": {\"category\": \"cat\"}}]}"},
{"user_content":"Get point with id 42 from the documents collection","tool_name":"get_point","tool_arguments":"{\"collection_name\": \"documents\", \"point_id\": 42}"},
{"user_content":"Set up a collection named vectors with 512 dimensions using euclidean distance","tool_name":"create_collection","tool_arguments":"{\"collection_name\": \"vectors\", \"vector_size\": 512, \"distance\": \"Euclid\"}"},
{"user_content":"Store two points in products: id 5 with vector [0.1, 0.9] and title phone, id 6 with vector [0.2, 0.7] and title laptop","tool_name":"upsert_points","tool_arguments":"{\"collection_name\": \"products\", \"points\": [{\"id\": 5, \"vector\": [0.1, 0.9], \"payload\": {\"title\": \"phone\"}}, {\"id\": 6, \"vector\": [0.2, 0.7], \"payload\": {\"title\": \"laptop\"}}]}"},
{"user_content":"Retrieve point 100 from vectors collection","tool_name":"get_point","tool_arguments":"{\"collection_name\": \"vectors\", \"point_id\": 100}"},
{"user_content":"Initialize a collection called text_embeddings with 768 dimensions using dot product distance","tool_name":"create_collection","tool_arguments":"{\"collection_name\": \"text_embeddings\", \"vector_size\": 768, \"distance\": \"Dot\"}"},
{"user_content":"Insert point id 10 into embeddings with vector [0.4, 0.6, 0.1] and text machine learning","tool_name":"upsert_points","tool_arguments":"{\"collection_name\": \"embeddings\", \"points\": [{\"id\": 10, \"vector\": [0.4, 0.6, 0.1], \"payload\": {\"text\": \"machine learning\"}}]}"},
{"user_content":"Fetch point 7 from products collection","tool_name":"get_point","tool_arguments":"{\"collection_name\": \"products\", \"point_id\": 7}"},
{"user_content":"Create collection named user_profiles with 256 vector dimensions and cosine similarity","tool_name":"create_collection","tool_arguments":"{\"collection_name\": \"user_profiles\", \"vector_size\": 256, \"distance\": \"Cosine\"}"},
{"user_content":"Add point 25 to text_embeddings with vector [0.7, 0.2, 0.9] and label document","tool_name":"upsert_points","tool_arguments":"{\"collection_name\": \"text_embeddings\", \"points\": [{\"id\": 25, \"vector\": [0.7, 0.2, 0.9], \"payload\": {\"label\": \"document\"}}]}"},
{"user_content":"Get the point with id 1 from documents","tool_name":"get_point","tool_arguments":"{\"collection_name\": \"documents\", \"point_id\": 1}"},
{"user_content":"Make a new collection files with 1024 dimensional vectors using euclidean distance metric","tool_name":"create_collection","tool_arguments":"{\"collection_name\": \"files\", \"vector_size\": 1024, \"distance\": \"Euclid\"}"},
{"user_content":"Upsert point id 50 in images with vector [0.8, 0.2] and metadata label car","tool_name":"upsert_points","tool_arguments":"{\"collection_name\": \"images\", \"points\": [{\"id\": 50, \"vector\": [0.8, 0.2], \"payload\": {\"label\": \"car\"}}]}"},
{"user_content":"Retrieve point 200 from embeddings","tool_name":"get_point","tool_arguments":"{\"collection_name\": \"embeddings\", \"point_id\": 200}"},
{"user_content":"Setup collection search_index with 128 dims and dot product","tool_name":"create_collection","tool_arguments":"{\"collection_name\": \"search_index\", \"vector_size\": 128, \"distance\": \"Dot\"}"},
{"user_content":"Insert three points into vectors: id 11 vector [0.1, 0.2] name A, id 12 vector [0.3, 0.4] name B, id 13 vector [0.5, 0.6] name C","tool_name":"upsert_points","tool_arguments":"{\"collection_name\": \"vectors\", \"points\": [{\"id\": 11, \"vector\": [0.1, 0.2], \"payload\": {\"name\": \"A\"}}, {\"id\": 12, \"vector\": [0.3, 0.4], \"payload\": {\"name\": \"B\"}}, {\"id\": 13, \"vector\": [0.5, 0.6], \"payload\": {\"name\": \"C\"}}]}"},
{"user_content":"Get point 500 from text_embeddings collection","tool_name":"get_point","tool_arguments":"{\"collection_name\": \"text_embeddings\", \"point_id\": 500}"},
{"user_content":"Build a collection named semantic_search with 384 vector size using cosine","tool_name":"create_collection","tool_arguments":"{\"collection_name\": \"semantic_search\", \"vector_size\": 384, \"distance\": \"Cosine\"}"},
{"user_content":"Store point 88 in files with vector [0.3, 0.7, 0.4, 0.6] and type pdf","tool_name":"upsert_points","tool_arguments":"{\"collection_name\": \"files\", \"points\": [{\"id\": 88, \"vector\": [0.3, 0.7, 0.4, 0.6], \"payload\": {\"type\": \"pdf\"}}]}"},
{"user_content":"Fetch point id 33 from images","tool_name":"get_point","tool_arguments":"{\"collection_name\": \"images\", \"point_id\": 33}"},
{"user_content":"Create a collection recommendations with 512 dimensions and euclidean distance","tool_name":"create_collection","tool_arguments":"{\"collection_name\": \"recommendations\", \"vector_size\": 512, \"distance\": \"Euclid\"}"},
{"user_content":"Add point 77 to documents with vector [0.6, 0.3, 0.1] and title research paper","tool_name":"upsert_points","tool_arguments":"{\"collection_name\": \"documents\", \"points\": [{\"id\": 77, \"vector\": [0.6, 0.3, 0.1], \"payload\": {\"title\": \"research paper\"}}]}"},
{"user_content":"Get point 444 from vectors collection","tool_name":"get_point","tool_arguments":"{\"collection_name\": \"vectors\", \"point_id\": 444}"},
]
This code constructs a comprehensive training dataset containing user queries paired with their corresponding Qdrant API function calls and properly formatted JSON arguments. Each dictionary entry represents a complete training example with user_content describing the natural language request, tool_name specifying which Qdrant operation to invoke, and tool_arguments containing the exact JSON parameters needed to execute that operation. The dataset covers various Qdrant operations including collection creation, point insertion, retrieval, searching, scrolling, and deletion, providing diverse examples that teach the model to map natural language instructions to correct function calls with appropriate arguments.
import json
from datasets import Dataset
from transformers.utils import get_json_schema
# --- Tool Definitions ---
def create_collection(collection_name: str, vector_size: int, distance: str) -> str:
"""
Creates a new collection in Qdrant with specified vector configuration.
Args:
collection_name: Name of the collection to create
vector_size: Dimension of vectors in the collection
distance: Distance metric for similarity search (Cosine, Euclid, or Dot)
"""
return "Collection created"
def upsert_points(collection_name: str, points: list) -> str:
"""
Insert or update points (vectors with metadata) in a collection.
Args:
collection_name: Name of the target collection
points: Array of points to upsert with id, vector, and payload
"""
return "Points upserted"
def delete_points(collection_name: str, point_ids: list) -> str:
"""
Delete points from a collection by their IDs.
Args:
collection_name: Name of the collection
point_ids: List of point IDs to delete
"""
return "Points deleted"
TOOLS = [
get_json_schema(create_collection),
get_json_schema(upsert_points),
get_json_schema(get_point),
get_json_schema(delete_points)
]
DEFAULT_SYSTEM_MSG = "You are a model that can do function calling with the following functions"
def create_conversation(sample):
return {
"messages": [
{"role": "developer", "content": DEFAULT_SYSTEM_MSG},
{"role": "user", "content": sample["user_content"]},
{"role": "assistant", "tool_calls": [{"type": "function", "function": {"name": sample["tool_name"], "arguments": json.loads(sample["tool_arguments"])} }]},
],
"tools": TOOLS
}
dataset = Dataset.from_list(qdrant_tool_calling)
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 50% training samples and 50% test samples
dataset = dataset.train_test_split(test_size=0.7, shuffle=True)
The above implementation establishes the complete tool infrastructure by defining Python functions for each Qdrant operation with detailed docstrings and type annotations, which are then converted into JSON schema format that the model can understand and use during training. The get_json_schema utility extracts function signatures, parameter types, and descriptions to create standardized tool definitions. The training data is transformed from the raw dictionary format into a conversational message structure following the chat template convention where each example contains a user message with the natural language request and an assistant response containing the structured tool call with function name and arguments. The formatted dataset is then split with 80% allocated for training and 20% reserved for evaluation, ensuring the model’s performance can be assessed on unseen examples during fine-tuning.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
# Print formatted user prompt
print("--- dataset input ---")
print(json.dumps(dataset["train"][0], indent=2))
debug_msg = tokenizer.apply_chat_template(dataset["train"][0]["messages"], tools=dataset["train"][0]["tools"], add_generation_prompt=False, tokenize=False)
print("--- Formatted prompt ---")
print(debug_msg)
The above code loads the pre-trained FunctionGemma model using automatic data type selection and device mapping for optimal memory usage across available hardware, while the eager attention implementation ensures compatibility though it may be slower than optimized alternatives. The tokenizer is loaded separately to handle text encoding and decoding using the model’s specific vocabulary and special tokens. The validation section prints device placement and data type information to verify correct hardware utilization, displays the first training example to inspect the data structure, and applies the chat template with tool definitions to show exactly how the model will see the formatted input during training, confirming that the message structure, tool schemas, and special tokens are correctly assembled before beginning the fine-tuning process.
def check_success_rate():
success_count = 0
for idx, item in enumerate(dataset['test']):
messages = [
item["messages"][0],
item["messages"][1],
]
inputs = tokenizer.apply_chat_template(messages, tools=TOOLS, add_generation_prompt=True, return_dict=True, return_tensors="pt")
out = model.generate(**inputs.to(model.device), pad_token_id=tokenizer.eos_token_id, max_new_tokens=128)
output = tokenizer.decode(out[0][len(inputs["input_ids"][0]) :], skip_special_tokens=False)
print(f"{idx+1} Prompt: {item['messages'][1]['content']}")
print(f" Output: {output}")
expected_tool = item['messages'][2]['tool_calls'][0]['function']['name']
if expected_tool in output:
print(" `-> ✅ correct!")
success_count += 1
else:
print(f" -> ❌ wrong (expected '{expected_tool}' missing)")
print(f"Success : {success_count} / {len(dataset['test'])}")
check_success_rate()
The above code function evaluates the model’s ability to generate correct tool calls by iterating through the test dataset and comparing predicted outputs against ground truth labels. For each test example, it constructs the input prompt with user message and tool definitions, generates the model’s response with a maximum of 128 new tokens, extracts only the newly generated content by slicing away the input tokens, and attempts to parse the output as JSON to extract the predicted function name and arguments. The evaluation considers a prediction successful only when both the tool name matches exactly and the parsed JSON arguments are structurally identical to the expected values, accounting for potential ordering differences. The function handles parsing failures gracefully by catching exceptions and counting them as incorrect predictions, finally reporting the overall success rate as both a fraction and percentage to provide a clear baseline metric before fine-tuning begins.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir="./functiongemma-270m-it-qdrant-ft", # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=8, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=False # push model to hub
)
This above implementation configures all hyperparameters and training settings using the SFTConfig class, which specializes in supervised fine-tuning workflows. The configuration sets the output directory for checkpoints and logs, limits sequence length to 512 tokens to balance memory usage and context coverage, disables packing to keep examples separate for clearer learning, and schedules training for 8 complete passes through the dataset. The batch size of 4 per device combined with 4 gradient accumulation steps creates an effective batch size of 16, allowing stable training while managing memory constraints through gradient checkpointing which trades computation for reduced memory by recomputing activations during backpropagation. The optimizer uses the fused AdamW implementation for faster training, applies the previously defined learning rate with a cosine decay schedule that gradually reduces the rate over time, and includes a warmup phase covering 10% of training to prevent early instability. The configuration enables bfloat16 precision for memory efficiency and faster computation, logs metrics every 10 steps for monitoring, performs evaluation and saves checkpoints at the end of each epoch, and disables HuggingFace Hub uploading and external reporting to keep training local.
from trl import SFTTrainer
# Create Trainer object
try:
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
print("Trainer created successfully")
trainer.train()
print("Training completed")
except Exception as e:
print(f"Error occurred: {type(e).__name__}")
print(f"Error message: {str(e)}")
import traceback
traceback.print_exc()
This instantiates the SFTTrainer object with the loaded model, configuration settings, training and evaluation datasets, and tokenizer for text processing, then executes the complete fine-tuning process. The try-except block provides robust error handling that catches any exceptions during trainer initialization or training execution, printing both the error type and detailed message along with the full traceback to facilitate debugging if issues arise. The trainer automatically handles the training loop including forward passes, loss calculation, backpropagation, optimizer steps, learning rate scheduling, gradient accumulation, checkpointing, and periodic evaluation on the test set according to the specified configuration. Status messages confirm successful trainer creation and training completion, allowing easy monitoring of the fine-tuning pipeline’s progression through its major phases.
import matplotlib.pyplot as plt
# Extract training and evaluation loss from the training history
train_losses = [log['loss'] for log in trainer.state.log_history if 'loss' in log]
eval_losses = [log['eval_loss'] for log in trainer.state.log_history if 'eval_loss' in log]
# Calculate epoch numbers for each loss value
epoch_train = [i/len(dataset['train']) for i in range(len(train_losses))]
epoch_eval = [i+1 for i in range(len(eval_losses))]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
The above creates a visualization of the training progression by extracting loss values from the trainer’s logged history and plotting them against training epochs. The training losses are recorded at regular intervals throughout each epoch based on the logging_steps configuration, while evaluation losses are computed once at the end of each epoch. The epoch values for training losses are calculated by dividing the step count by the dataset size to properly align them on the time axis, while evaluation losses are simply incremented by whole epoch numbers. The resulting line plot displays both training and validation curves together, allowing visual assessment of model convergence, identification of potential overfitting where validation loss increases while training loss decreases, and verification that the learning rate schedule and other hyperparameters are producing the expected training dynamics with a grid overlay and legend for improved readability.
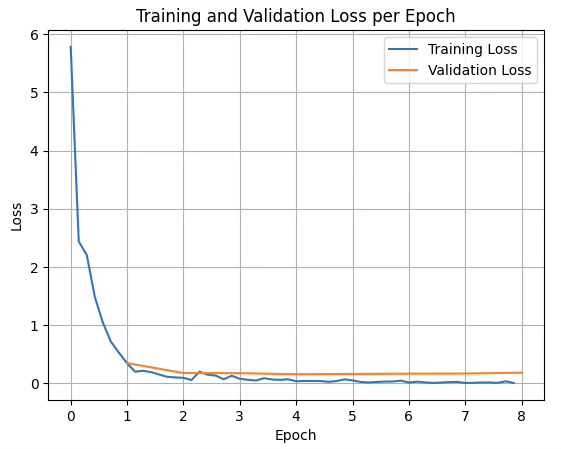
training and validation loss propagation while fine-tuning FunctionGemma
The Result:

Before fine-tuning

After fine-tuning
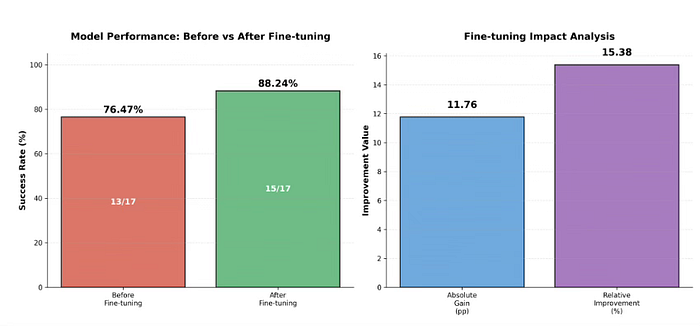
Fine-tuning Performance Results:
Before Fine-tuning: 13/17 correct predictions (76.47% success rate) After Fine-tuning: 15/17 correct predictions (88.24% success rate)
Improvement Achieved:
Absolute gain: 11.76 percentage points Relative improvement: 15.38% Additional correct predictions: 2 out of 17 test cases
validating the finetuned model with the base model
Conclusion:
Finally, I want to conclude by saying that this article was intentionally designed to be fully hands on, focusing on what it actually takes to turn a language model into something that can be executed safely and predictably. Instead of treating FunctionGemma as a conversational model, we shaped it into a control layer that understands intent and produces structured Qdrant actions that real systems can rely on.
What this hands-on exercise ultimately demonstrates is a practical direction for applied GenAI. Small, well-trained models can live close to the data, run locally, and handle clearly defined actions with high confidence. When combined with larger models only where deeper reasoning is required, this approach leads to systems that are faster, more private, and easier to operate. The value is not in the model alone, but in how deliberately it is trained and placed within the system.
Comments
Loading comments…