AI-generated code has transitioned from a novelty to the silent default. What began as simple autocomplete suggestions has evolved into full-feature synthesis, where entire service layers are authored by non-deterministic models. This shift has created a dangerous “surface quality” trap: AI-generated artifacts often look polished, pass basic linting, and compile without error, yet hide systemic behavioral risks.
For technical leaders, the challenge is no longer about adoption — it is about verification. We are moving away from Empirical Testing (runtime checks) toward Analytical Verification (compile-time proof and multi-agent adversarial loops). To navigate this, we must evolve our architectural guardrails to treat AI-generated code not just as untrusted, but as a unique risk vector that requires a new class of verifiable systems.
Stop Treating AI Like a Junior Developer
The most pervasive error in modern DevSecOps is the “Junior Developer” mental model. We treat AI as a human apprentice that simply needs guidance. This is a category error. Unlike a human junior, an AI possesses no internal mental model of your organization’s threat posture or the security implications of its choices. It operates purely on statistical plausibility.
Instead of seeing this lack of context as a liability, senior strategists are leveraging the “Zero-Context Engineer” constraint as a mandatory role separation. By architecting requirements so explicit that an agent with zero knowledge of the codebase can follow them literally, teams are achieving a higher degree of epistemic success. This constraint prevents “context rot” and forces the elimination of the ambiguity where security vulnerabilities typically reside.
AI does not reason about threat models. It does not understand your organization’s security posture. It predicts plausible code, not safe behavior.
Review the Behavior, Ignore the Syntax
Traditional code reviews are failing because they prioritize cosmetic syntax — variable naming and style — areas where AI already excels at producing clean-looking boilerplate. AI-related risks are fundamentally behavioral and emerge from complex component interaction integrity rather than isolated dangerous lines of code.
When auditing AI artifacts, the focus must shift from “Does this look reasonable?” to “What assumptions is this code making about state and identity?” Reviewers should specifically interrogate the following Behavioral Failures:
- Partial Authorization: Permission checks that are present but only enforced on specific, linear code paths.
- State Trust: APIs that implicitly trust client-provided state which should be strictly server-derived or validated against a source of truth.
- Linear Optimizations: Logic that assumes a predictable A-to-B flow, leaving the system vulnerable to attackers who exploit non-linear execution or request replays.
- Hidden Bypasses: Temporary logic or hardcoded defaults the AI inserted to make a function work functionally while failing defensively.
AI models tend to flatten these distinctions. AI often optimizes for linear flows; attackers exploit non-linear ones.
The Rise of the Self-Healing Pipeline
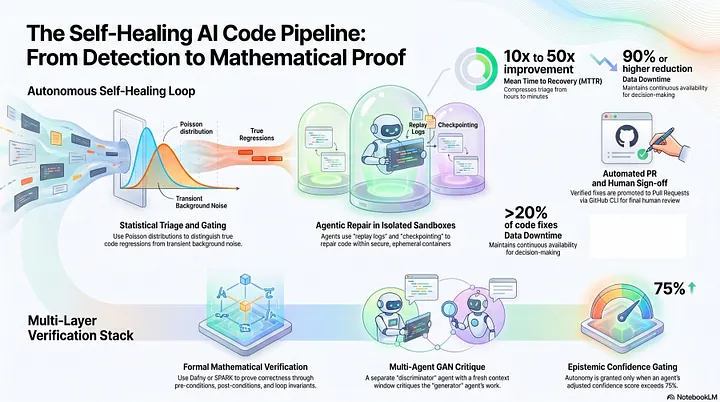
We are entering the era of the “Self-healing CI,” where pipeline failures are no longer terminal states requiring immediate human triage. Instead, we are building automated feedback loops that transition from manual debugging to autonomous remediation.
This 6-step workflow is anchored by the Model Context Protocol (MCP), which serves as the critical bridge giving AI agents access to the filesystem, CI logs, and workflow metadata:
- Failure: The CI pipeline identifies a build or test regression.
- 2. Diagnosis: An AI agent uses an MCP Server to ingest logs and metadata, localizing the fault.
- 3. Repair: The agent applies a fix and pushes it to a dedicated “self-heal” branch.
- 4. Validation: The CI pipeline re-runs on the self-heal branch.
- 5. Promotion: If successful, a second promotion triggers the creation of a Pull Request.
- 6. Review: A human engineer conducts a final validation before merging.
Self-healing CI is a new pattern that uses AI to automatically diagnose failures, apply code changes, re-run the pipeline, and open a pull request.
Mathematical Proof is the New Unit Test
Testing can reveal the presence of bugs, but for safety-critical systems, it cannot prove their absence. LLMs are now making formal verification — using languages like Dafny or SPARK — accessible to mainstream engineering. This shift replaces dynamic runtime checks with “static test cases”: assertions checked by an SMT-based verifier at compile-time.
Research on “Generate — Check — Repair — Minimize” workflows has demonstrated a 98.2% success rate in generating correct formal annotations. However, LLMs are prone to “annotation bloat,” producing verbose solutions that increase unowned technical debt. Applying a Minimization Procedure is essential; recent studies show that automatically removing redundant segments can reduce annotation lines of code (LOC) by 58%, ensuring the resulting proof remains maintainable and focused.
Our approach benefits from strong, machine checkable oracles, namely the Dafny SMT-based verifier and statically checked test assertions.
Architecture as Argument (The GAN Pattern)
To achieve architectural integrity, we are adopting the “Generative Adversarial Network” (GAN) pattern for multi-agent development. This framework enforces a Mandatory Role Separation where the “Generator” (the agent writing code) and the “Discriminator” (the agent reviewing it) operate in isolated context windows.
To prevent the reviewer from inheriting the generator’s blind spots, it must have zero knowledge of the author’s reasoning. Before code is promoted, an Introspection Layer calculates an Adjusted Confidence Score to determine the level of autonomy:
Adjusted Confidence = Stated Confidence — (5% x Gaps) + (2% x Alternatives)
- Score < 50%: ESCALATE_HUMAN; the diagnosis is too uncertain for automation.
- Score 50 — 75%: Authorized for staging validation; requires human sign-off for merge.
- Score > 75%: Authorized for autonomous deployment with a rollback window.
The adversarial tension is what produces quality.
Conclusion:
Speed Changes Responsibility, Not Risk
AI significantly reduces the friction to creating complexity, but it does not reduce the human responsibility to defend it. Code without explicit ownership becomes technical debt the moment it is committed. Ownership is now a survivability requirement; as we transition from “writers” to “validators,” the ultimate risk is that we stop interrogating the machines.
The question for every engineering leader is no longer how fast we can ship, but how much unowned code is currently accumulating in your production environment. When the underlying statistical assumptions of the AI finally break, who will be responsible for the fallout?
Comments
Loading comments…